
中国人民大学、北京邮电大学和上海人工智能实验室的研究人员推出RefAVS(参照音频-视觉分割),依据融合了多模态提示(包括音频和视觉描述)的自然语言表达,对视觉场景中的目标物进行分割。研究团队还创建了首个RefAVS基准数据集,首次为与多模态提示表达相匹配的目标物体提供了像素级标注。
例如,你正在观看一个音乐会的视频,视频中有多个乐器和音乐家。如果一个系统能够理解你说出“那个正在弹钢琴的人”这样的指令,并在视频中准确地识别和分割出正在弹钢琴的那个人,那么这个系统就完成了Ref-AVS任务。这个任务的挑战在于,它需要同时处理视觉信息(如图像中的人物和乐器)和音频信息(如乐器发出的声音),并结合自然语言描述来精确地定位和分割目标物体。
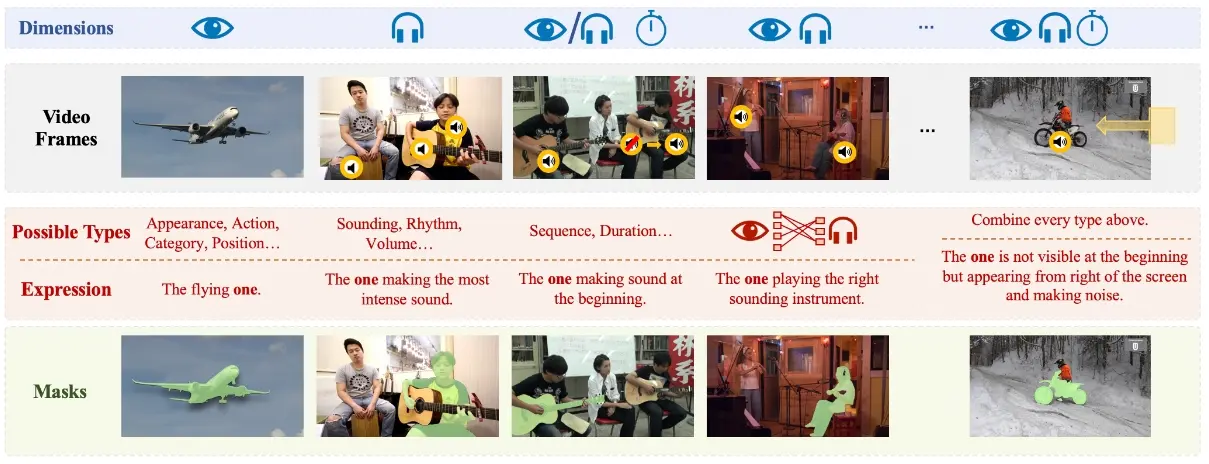
主要功能
- 多模态线索理解:系统能够理解和处理音频、视觉和文本信息。
- 物体分割:系统能够根据给定的描述在视频中精确地分割出目标物体。
- 动态场景处理:系统能够在动态变化的音频-视觉场景中进行实时分析和分割。
主要特点
- 多模态融合:通过结合音频、视觉和文本信息,提高对场景的理解能力。
- 端到端框架:设计了一个完整的框架,从多模态信息的提取到最终的物体分割,整个过程是连贯的。
- 鲁棒性:系统能够在复杂和动态的音频-视觉场景中稳定地工作,即使在存在多个声源和多个语义的情况下。
工作原理
- 数据集构建:首先构建了一个包含多模态线索的基准数据集(Ref-AVS Bench),提供了像素级注释,用于描述对应多模态线索表达式中的对象。
- 多模态表示:将音频输入分割成1秒间隔的片段,使用VGGish编码音频表示;视觉表示通过预训练的Swin-base模型从视频输入中提取;文本表达式特征通过RoBERTa提取。
- 时序双模态变换器:通过自注意力机制融合不同模态的特征,同时引入缓存记忆来捕捉时间变化。
- 多模态提示:利用多模态线索特征作为提示,通过交叉注意力机制引导视觉基础模型进行分割。
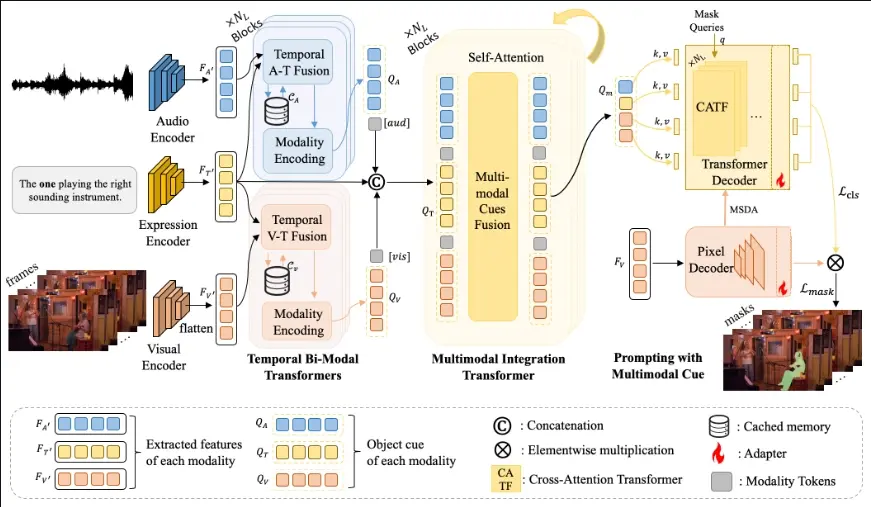
具体应用场景
- 电影和电视制作:在电影和电视节目的后期制作中,Ref-AVS技术可以帮助自动分割和编辑特定的物体或人物。
- 增强现实:在增强现实应用中,Ref-AVS可以帮助用户通过语音指令来交互和操作虚拟环境中的物体。
- 视频内容分析:在视频监控或内容分析中,Ref-AVS技术可以用于自动识别和跟踪视频中的关键物体或事件。
- 辅助听力障碍人士:通过音频和视觉的结合,帮助听力障碍人士更好地理解和参与到视频内容中。
论文还详细介绍了Ref-AVS数据集的构建过程、表达式的生成和分级、以及模型的实现细节。这些内容为未来的研究提供了一个坚实的基础,并展示了该方法在不同测试子集上的有效性。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











