英伟达和麻省理工学院的研究人员推出新型生成模型DisCo-Diff,它用于增强连续扩散模型(Diffusion Models, DMs)的性能。扩散模型是一种强大的数据生成方法,但它们通常需要将复杂的数据分布编码到一个简单的高斯分布中,这在技术上是一个挑战。DisCo-Diff通过引入离散的潜在变量来简化这一任务,这些离散变量与连续的潜在变量相结合,以更好地捕捉数据的复杂性和多模态特性。
例如,我们想生成一系列具有特定风格的图像,使用DisCo-Diff可以在不需要大量计算资源的情况下,通过调整离散潜在变量来捕捉图像的风格和布局,同时保持图像细节的丰富性。在分子对接中,DisCo-Diff可以帮助科学家快速预测药物分子与靶标蛋白结合的最佳方式,加速药物的研发过程。
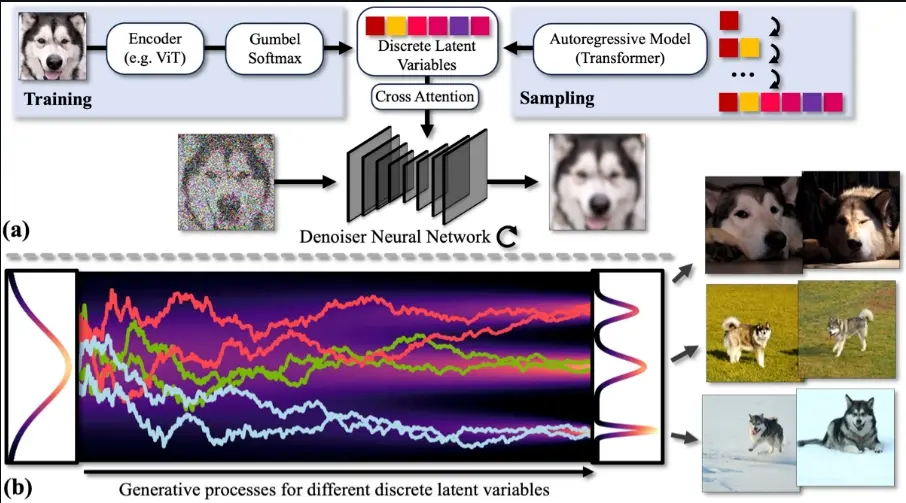
离散-连续潜变量扩散模型(DisCo-Diff)通过集成可学习的离散潜变量(由编码器推断得到)并实现DM与编码器的端到端训练,增强了DM的功能。值得注意的是,DisCo-Diff并不需要预训练网络的支持,这赋予了该框架更广泛的通用性。通过减少DM生成过程中的常微分方程(ODE)曲度,离散潜变量极大地简化了学习从噪声到数据复杂映射的任务。此外,研究人员还配备了一个额外的自回归变压器来描绘离散潜变量的分布情况,这项工作由于DisCo-Diff仅需少量小规模码本的离散变量而变得相对直接。
主要功能和特点:
- 结合离散和连续潜在变量:DisCo-Diff的核心创新是将离散潜在变量与连续扩散模型相结合,其中离散变量通过编码器推断,并与扩散模型一起端到端训练。
- 简化学习过程:通过引入离散变量,DisCo-Diff减少了扩散模型生成ODE(普通微分方程)的曲率,从而简化了学习过程。
- 通用性:该方法不依赖于预训练的网络,使其具有普遍适用性。
- 提高性能:在多个数据集和任务上,DisCo-Diff通过引入离散潜在变量,一致性地提高了模型性能。
工作原理: DisCo-Diff的工作流程包括两个主要阶段:
- 训练阶段:首先,使用编码器从数据中推断出离散潜在变量,并将这些变量与连续潜在变量一起输入到扩散模型中进行端到端的训练。编码器通过网络学习如何将数据编码为离散潜在变量,而扩散模型学习如何根据这些变量生成数据。
- 推理阶段:在生成新样本时,首先通过一个自回归模型采样得到离散潜在变量,然后使用扩散模型的逆过程生成数据。
具体应用场景:
- 图像合成:在ImageNet数据集上,DisCo-Diff能够生成具有特定类别标签的高质量图像。
- 分子对接:在药物发现领域,DisCo-Diff可以用于预测小分子与蛋白质结合的3D结构,这对于设计新药至关重要。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











