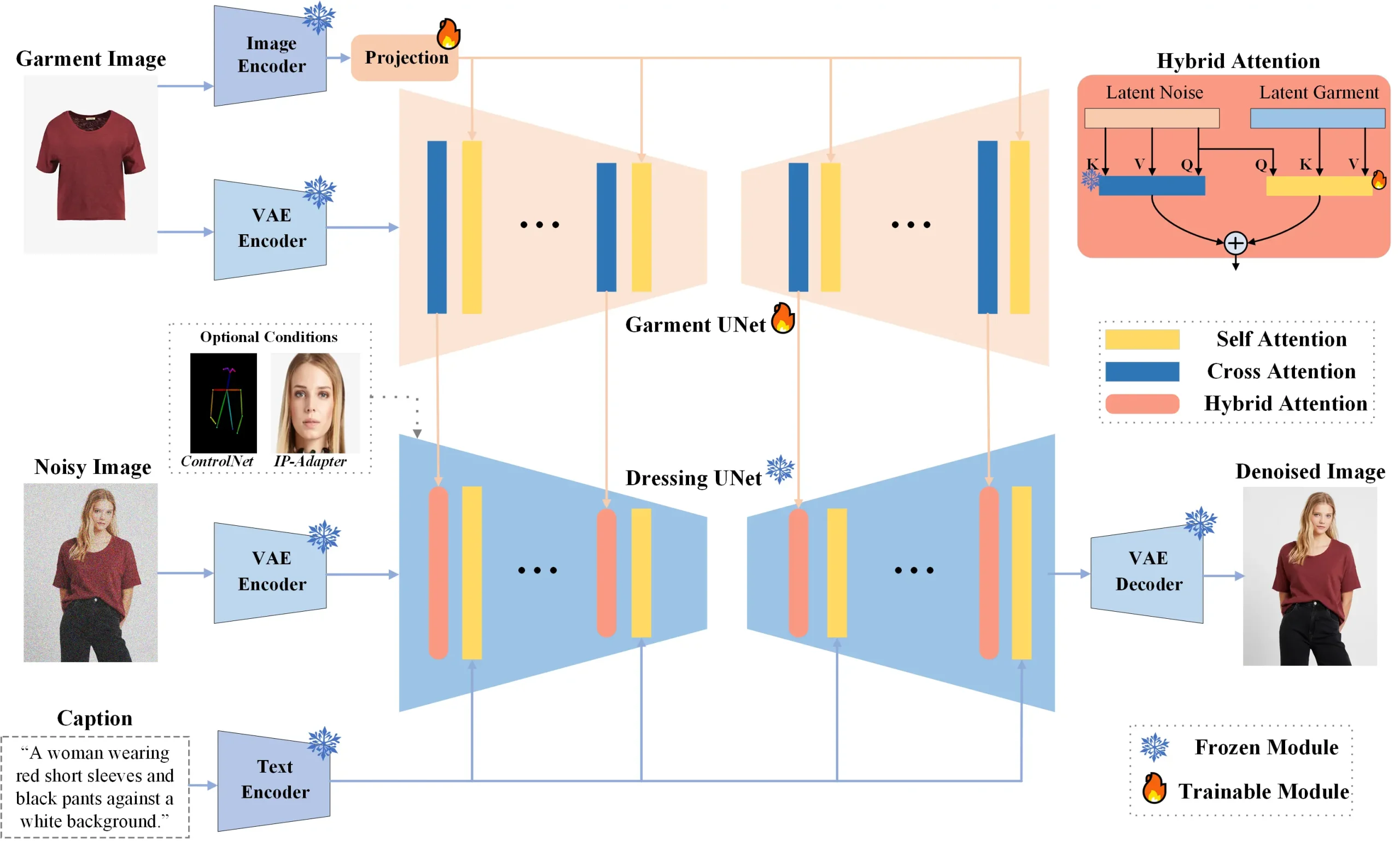
南京理工大学、华为、 腾讯人工智能实验室和南京大学的研究人员推出可定制的虚拟试衣系统IMAGDressing-v1,这个系统可以帮助用户在线上购物时,更真实地预览服装在不同人身上的效果。IMAGDressing-v1整合了服装UNet,该网络利用CLIP捕获语义特征,并借助VAE获取纹理细节。我们创新设计了混合注意力模块,它结合了静态自注意力与可训练交叉注意力机制,以有效融合服装UNet提取的特征至稳定的去噪UNet中,使用户仅凭文本就能自如引导不同场景的生成。
- 项目主页:https://imagdressing.github.io
- GitHub:https://github.com/muzishen/IMAGDressing
- 模型:https://huggingface.co/feishen29/IMAGDressing
- Demo:https://sf.dictdoc.site
此外,IMAGDressing-v1具备高度扩展性,可通过集成ControlNet或IP-Adapter等插件,进一步提升图像生成的多样性和操控性。针对数据稀缺挑战,研究团队还推出了交互式服装匹配数据集(Interactive Garment Pairing,IGPair),该数据集包含超30万组服装与穿戴效果配对,并确立了一套标准化的数据集构建流程。
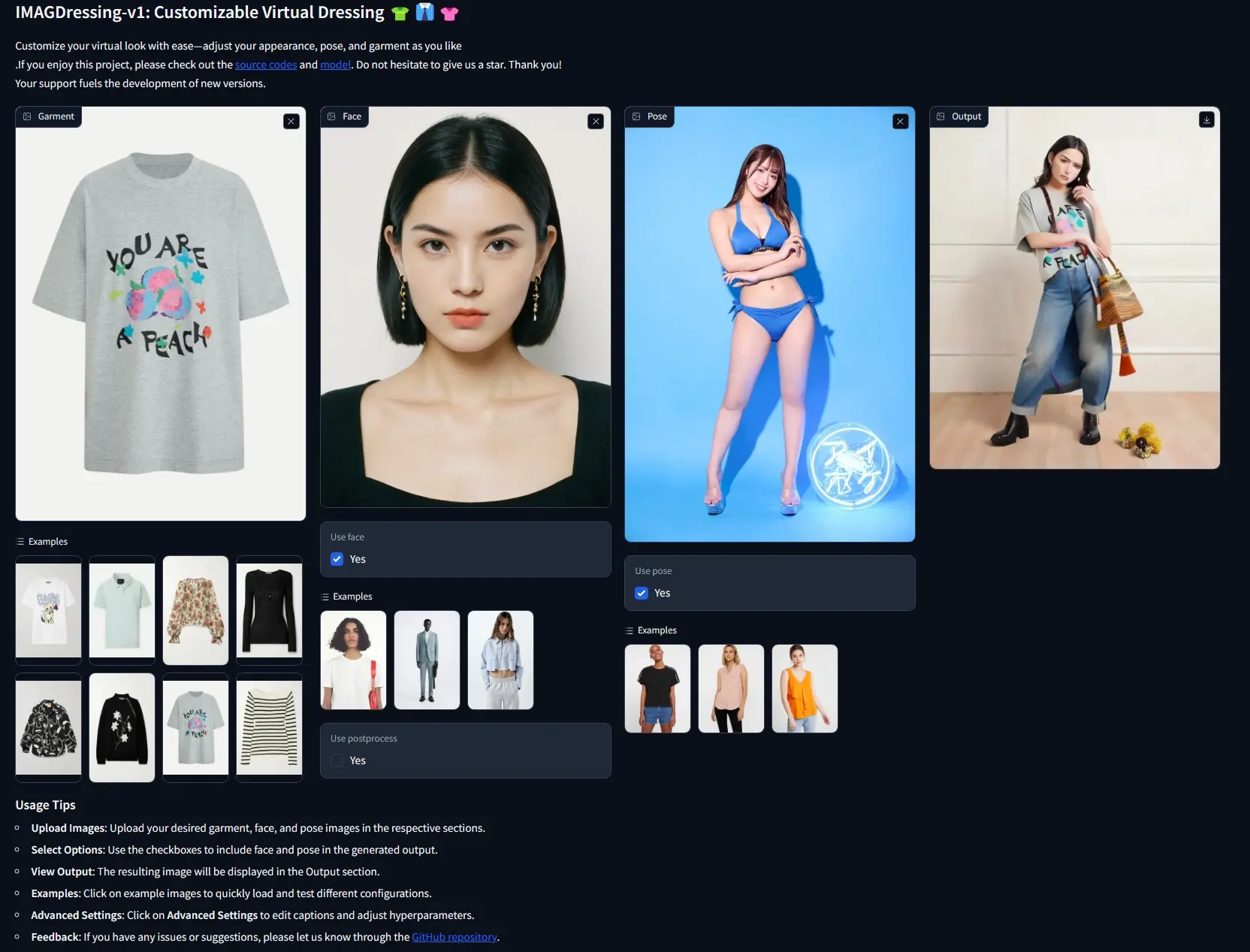
例如,你是一名在线服装店的店主,你希望展示你的服装在不同模特身上的效果。你可以使用IMAGDressing-v1系统上传服装的照片和你希望展示的模特的照片,系统会生成模特穿着这些服装的虚拟图像。这样,顾客就可以在购买前看到服装在不同体型和风格的人身上的样子。
主要功能
- 虚拟试衣:用户可以上传自己的照片,系统会生成他们穿着特定服装的虚拟图像。
- 服装特征提取:系统能够从服装图片中提取出服装的语义特征和纹理特征。
- 场景控制:用户可以通过文本提示控制生成图像的场景,比如背景、姿势等。
- 兼容性:IMAGDressing-v1可以与其他扩展插件(如ControlNet和IP-Adapter)结合使用,增强生成图像的多样性和可控性。
主要特点
- 高保真度:系统生成的图像具有高质量的视觉效果,能够真实地反映服装的纹理和细节。
- 实时渲染:系统能够在实时或接近实时的速度下生成图像,提高了用户体验。
- 灵活性:系统不仅能够处理固定姿势的服装展示,还能够根据用户的需要生成不同姿势和场景下的服装效果。
- 数据集:为了解决数据不足的问题,研究者们还发布了一个包含超过30万对服装和穿着图像的交互式服装配对(IGPair)数据集。
工作原理
IMAGDressing-v1系统基于一种名为"latent diffusion models"的技术,它通过以下步骤工作:
- 服装UNet:这个模块用于捕捉服装的语义特征和纹理特征。
- 混合注意力模块:包括一个冻结的自注意力模块和一个可训练的交叉注意力模块,用于将服装特征整合到去噪UNet中。
- 去噪UNet:这个模块用于根据服装特征和文本提示生成最终的图像。
- 文本编码器:将文本提示转换为可以用于图像生成的嵌入表示。
- 图像编码器:将服装图像转换为系统的内部表示,以便进行进一步的处理。
具体应用场景
- 电子商务:在线服装店可以使用IMAGDressing-v1来展示服装在不同模特身上的效果,帮助顾客做出购买决策。
- 娱乐:电影和游戏制作中,可以使用这个系统来快速生成角色的服装效果。
- 个性化推荐:根据用户的体型和风格偏好,系统可以推荐适合他们的服装。
- 虚拟试衣间:在虚拟试衣间中,顾客可以上传自己的照片,尝试不同的服装组合。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...











