
蚂蚁集团和清华大学的研究人员提出了Mimir,这是一个端到端的训练框架,旨在解决当前视频扩散模型在文本理解方面的不足,并充分利用大语言模型(LLMs)的强大文本处理能力。Mimir通过引入精心设计的标记融合器,协调文本编码器和LLMs的输出,使得T2V模型能够更好地理解和生成高质量的视频片段。

以下是Mimir的关键技术和贡献:
1. 背景与挑战
- 文本作为关键控制信号:在视频生成中,文本描述因其叙事性质而显得尤为重要。当前的视频扩散模型主要依赖于文本编码器提取的特征,但在文本理解方面仍显不足。
- LLMs的优势:最近大语言模型的成功展示了仅解码器变换器的强大功能,为文本到视频生成提供了三个明显的好处:
- 精确文本理解:由于其卓越的可扩展性,LLMs能够更准确地理解复杂的文本描述。
- 超越输入文本的想象力:通过下一个标记预测,LLMs可以生成超出输入文本的内容,增加了生成视频的多样性和创造性。
- 灵活优先考虑用户兴趣:通过指令调优,LLMs可以根据用户的特定需求和兴趣进行调整,提供更加个性化的生成结果。
- 特征分布差距:然而,两种不同文本建模范式(文本编码器和LLMs)之间的特征分布差距阻碍了LLMs在现有T2V模型中的直接应用。
2. Mimir的核心技术创新
为了克服这一挑战,Mimir引入了以下关键技术:
- 端到端训练框架:Mimir是一个端到端的训练框架,旨在将LLMs的强大文本处理能力与视频生成模型相结合,实现更高质量的视频生成。
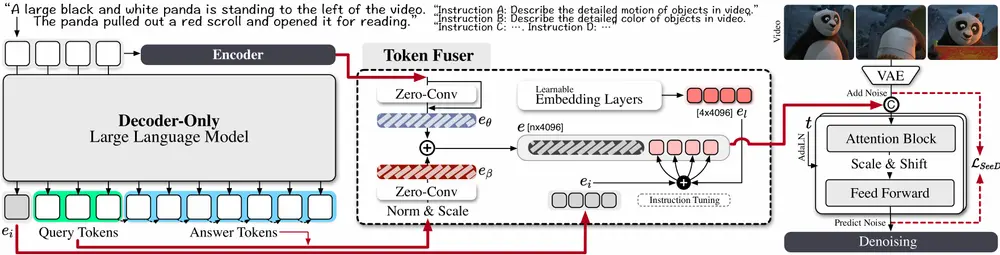
- 精心设计的标记融合器:Mimir的核心是其精心设计的标记融合器,该融合器能够协调文本编码器和LLMs的输出,弥合两者之间的特征分布差距。具体来说:
- 特征对齐:标记融合器通过学习将文本编码器的特征映射到与LLMs输出相兼容的空间,确保两者之间的平滑过渡。
- 信息融合:融合器不仅对齐了特征分布,还结合了两者的优势,使得T2V模型能够充分利用学习到的视频先验知识,同时利用LLMs的文本相关能力。
- 动态适应:标记融合器能够在训练过程中动态调整,以适应不同类型的文本描述和视频生成任务,增强了模型的灵活性和泛化能力。
3. 实验结果与性能提升
广泛的定量和定性实验结果证明了Mimir在生成高质量视频并具备出色文本理解方面的有效性,特别是在以下几个方面表现出色:
- 高质量视频生成:Mimir生成的视频在视觉质量和细节表现上显著优于现有的T2V模型,能够准确反映输入文本的描述。
- 出色的文本理解:Mimir能够更准确地理解复杂的文本描述,尤其是在处理短描述时表现出色,能够捕捉到文本中的细微差别和隐含信息。
- 管理动态变化:Mimir在处理视频中的动态变化方面表现出色,能够生成连贯且自然的运动序列,避免了常见的跳跃或不自然的现象。
- 个性化生成:通过指令调优,Mimir可以根据用户的特定需求和兴趣生成个性化的视频内容,提供了更高的灵活性和用户体验。
主要功能和特点
- 精确文本理解:Mimir能够精确理解文本提示中的语义信息,包括对象、颜色、动作和空间关系。
- 时空语义生成:模型不仅生成静态图像,还能生成具有一致时空语义的视频内容。
- Token Fuser:一个创新的组件,用于融合不同分布的编码器和解码器生成的语义特征。
- 端到端训练框架:Mimir在一个统一的框架内进行训练,无需复杂的适配器或额外的编码器。
工作原理
Mimir的工作原理包括以下几个关键步骤:
- 文本编码:使用文本编码器和解码器(decoder-only LLM)处理输入的文本提示,生成文本特征。
- Token Fuser:通过归一化和可学习的缩放因子处理解码器生成的Token,然后使用Zero-Conv层保持原始的语义空间,最终将编码器和解码器的Token融合。
- 语义稳定器:通过初始化可学习的Token并将其与指令Token结合,来稳定文本特征的波动。
- 视频生成:将融合后的Token输入到视频扩散模型中,生成与文本提示相匹配的视频内容。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











