
Jina AI推出文本嵌入模型jina-embeddings-v3,这是一个具有 5.7 亿参数的新型文本嵌入模型,它在多语言数据和长上下文检索任务上实现了最先进的性能,支持的最大上下文长度达到 8192 个标记。该模型包括一组针对特定任务的LoRA,用于生成高质量的嵌入,适用于查询-文档检索、聚类、分类和文本匹配。此外,Matryoshka 表示学习被整合到训练过程中,允许灵活地截断嵌入维度而不损害性能。
例如,你正在开发一个多语言的问答系统,用户可以用不同的语言提问。jina-embeddings-v3可以帮助你的系统理解问题的含义,并在数据库中检索最相关的答案,无论这些文档是英文、中文还是其他语言。此外,如果用户的问题很长或包含多个部分,模型仍然能够有效地处理并找到正确的信息。
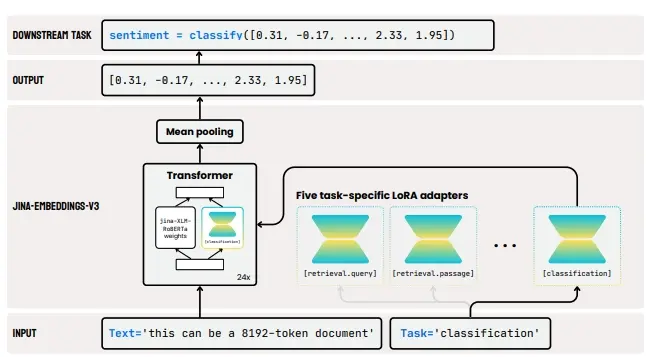
主要功能:
jina-embeddings-v3的主要功能是将文本文档转换为高维向量,这些向量能够捕捉文档之间的语义关系,并在空间上表示这些关系。这使得模型在各种下游任务,如分类、检索和聚类中都非常有用。
主要特点:
- 多语言支持: 模型能够处理多种语言的文本,使其在国际化应用中非常有用。
- 长文本处理: 支持长达8192个令牌的文本,适合处理长篇文章或文档。
- 任务特定优化: 使用了任务特定的低秩适配器(LoRA),可以根据不同的任务生成特定的嵌入。
- Matryoshka表示学习: 允许在不牺牲性能的情况下灵活地截断嵌入维度。
工作原理:
jina-embeddings-v3通过以下几个步骤工作:
- 预训练: 使用大量多语言文本数据进行预训练,以学习语言的基本结构和语义。
- 任务特定适配: 通过训练特定的LoRA适配器来优化模型在特定任务(如分类、检索等)上的表现。
- 嵌入生成: 对输入文本进行编码,生成能够表示文本内容和语义的向量。
- 下游任务应用: 将生成的嵌入向量用于各种任务,如通过相似性搜索进行文档检索。
具体应用场景:
- 信息检索系统: 在搜索引擎中,可以使用jina-embeddings-v3来提高文档相关性的判断。
- 内容推荐: 在推荐系统中,通过文本嵌入来理解用户兴趣和内容特征,提供个性化推荐。
- 自然语言处理: 在机器翻译、情感分析等NLP任务中,使用文本嵌入来提高模型的性能。
- 文档聚类: 在处理大量文档时,通过聚类相似文档来组织和归档信息。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











