多模态音乐生成旨在从多种输入模态(如文本、视频和图像)中生成音乐。尽管现有方法通过使用通用嵌入空间进行多模态融合,在其他任务中表现出色,但在多模态音乐生成中仍面临以下挑战:
- 数据稀缺:高质量的多模态音乐数据集较为稀少,难以获取大规模标注数据。
- 跨模态对齐弱:不同模态之间的语义差距较大,导致生成的音乐与输入模态之间的对齐效果不佳。
- 可控性有限:用户难以精确控制生成音乐的风格、情感等属性。
为了解决这些问题,中国科学院信息工程研究所、中国科学院大学网络空间安全学院、上海人工智能实验室、上海交通大学、爱丁堡大学、美图公司 MT 实验室、香港中文大学 和北京航空航天大学的研究人员提出了一种名为 Visuals Music Bridge (VMB)的 多模态音乐生成系统。该系统能够从多种输入模态(如文本、图像和视频)中生成音乐。VMB的核心在于使用文本和音乐作为显式的桥梁,以实现不同模态之间的有效对齐和音乐生成。
例如,你有一个描述森林的宁静早晨的视频,VMB可以根据视频的视觉内容生成与之相匹配的背景音乐。同样,如果你提供一段描述激动人心的赛车比赛的文本,VMB也能够生成相应的音乐来增强文本的情感和氛围。
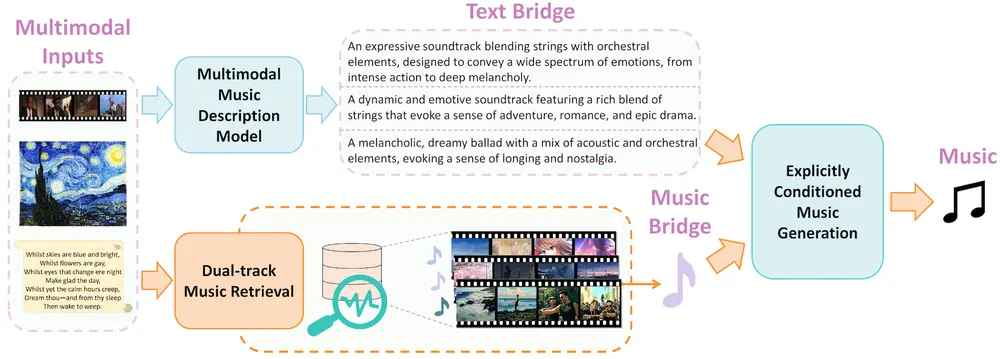
方法论
1. 显式文本和音乐桥梁
VMB 的核心思想是通过显式的文本和音乐桥梁来实现更好的多模态对齐。具体来说:
- 文本桥梁:通过将视觉输入(如图像或视频)转换为详细的文本描述,提供一个中间表示,帮助模型理解输入模态的语义信息。
- 音乐桥梁:通过双轨音乐检索模块,结合广泛和目标检索策略,找到与输入模态最匹配的音乐片段,作为生成音乐的参考。
2. 多模态音乐描述模型
为了构建文本桥梁,VMB 引入了一个 多模态音乐描述模型,该模型能够将视觉输入(如图像或视频)转换为详细的文本描述。具体步骤如下:
- 视觉特征提取:使用预训练的视觉编码器(如 CLIP 或 VGG)提取输入图像或视频的关键特征。
- 文本生成:基于提取的视觉特征,使用文本生成模型(如 T5 或 BART)生成详细的文本描述,涵盖场景、情感、动作等信息。
- 文本桥梁:生成的文本描述作为中间表示,帮助模型更好地理解输入模态的语义,并将其与音乐生成过程联系起来。
3. 双轨音乐检索模块
为了构建音乐桥梁,VMB 设计了一个 双轨音乐检索模块,该模块结合了广泛检索和目标检索策略,以提供更精准的音乐参考。具体步骤如下:
- 广泛检索:从大规模音乐数据库中检索与输入模态相关的音乐片段,确保覆盖广泛的音乐风格和情感。
- 目标检索:根据用户提供的特定要求(如音乐风格、节奏、情感等),进一步筛选出最符合需求的音乐片段。
- 音乐桥梁:最终选择的音乐片段作为生成音乐的参考,帮助模型在生成过程中保持与输入模态的一致性。
4. 显式条件音乐生成框架
基于文本和音乐桥梁,VMB 设计了一个 显式条件音乐生成框架,用于生成高质量的音乐。该框架包括以下组件:
- 条件编码器:将文本桥梁和音乐桥梁作为条件输入,编码成隐含表示。
- 音乐生成器:基于条件编码器的输出,生成符合输入模态的音乐。生成器可以是基于自回归模型(如 Transformer)或非自回归模型(如 Diffusion Model)。
- 可控性增强:通过引入用户控制参数(如音乐风格、节奏、情感等),用户可以在生成过程中灵活调整音乐的属性,提升生成结果的定制化能力。
实验结果
VMB 在多个多模态音乐生成任务中展示了卓越的性能,具体包括:
- 视频到音乐:VMB 能够根据视频内容生成与场景和情感高度一致的背景音乐,显著提升了音乐质量。
- 图像到音乐:VMB 根据图像中的视觉元素(如风景、人物、动作等)生成相应的音乐,增强了音乐与图像的对齐效果。
- 文本到音乐:VMB 根据给定的文本描述生成符合语义的音乐,支持用户通过文本精确控制音乐的情感和风格。
- 可控音乐生成:VMB 提供了丰富的用户控制选项,允许用户在生成过程中灵活调整音乐的风格、节奏、情感等属性,满足个性化需求。
实验结果表明,VMB 在音乐质量、模态对齐和定制化方面显著优于现有的多模态音乐生成方法。VMB 为可解释和表现力强的多模态音乐生成设定了新标准,并在各种多媒体领域中具有广泛的应用潜力。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











