校正流模型(如 Flux)在图像生成中已成为主导方法,展示了高质量图像合成的卓越能力。然而,尽管它们在视觉生成中表现出色,校正流模型在图像的解耦编辑方面往往表现不佳。这一限制阻碍了在不影响图像无关部分的情况下进行精确的属性特定修改的能力。为了克服这一挑战,弗吉尼亚理工大学的研究人员引入了 FluxSpace,一种利用校正流变换器(如 Flux)生成图像的表示空间进行域无关图像编辑的方法。
FluxSpace的核心能力在于能够在不同领域(如人、动物、汽车)上进行语义编辑,并且能够处理更复杂的场景,例如街道图像。该方法能够根据关键词(例如“卡车”将汽车转变为卡车)应用编辑,并且提供了解耦的编辑能力,这意味着在不提供手动掩码的情况下,也能针对原始图像的特定方面进行编辑。此外,FluxSpace不需要任何训练,可以在推理时应用所需的编辑。

例如,你有一张一个男人的照片,想要改变他的面部表情,比如添加一个微笑,或者改变他的配饰,比如添加一副眼镜。使用FluxSpace,你只需要提供一个描述这些变化的文本提示,比如“微笑”或“眼镜”,系统就能在不改变图像其他无关方面的情况下,精确地应用这些编辑。
FluxSpace 的核心思想
FluxSpace 通过利用校正流模型中变换器块学习到的表示,提出了一组语义可解释的表示,能够实现从细粒度图像编辑到艺术创作的广泛图像编辑任务。该方法提供了一种可扩展且有效的图像编辑方案,并具备解耦编辑能力,允许用户在推理时应用所需的编辑,而无需任何训练或手动提供掩码。
主要功能
- 文本引导的图像编辑:使用文本提示来指导图像的编辑过程。
- 解耦编辑能力:能够对图像的特定属性进行精确修改,而不会影响图像的其他方面。
- 无需训练:在推理时直接应用编辑,无需额外的训练步骤。
主要特点
- 语义可解释性:通过利用变换器块内的表示学习,FluxSpace提供了一组语义可解释的表示,使得广泛的图像编辑任务成为可能。
- 灵活性和有效性:支持从细粒度的图像编辑到艺术创作的广泛图像编辑任务。
- 无需掩码的编辑:不需要用户提供掩码或特定区域的标记,即可进行精确编辑。
方法论
1. 双层编辑框架
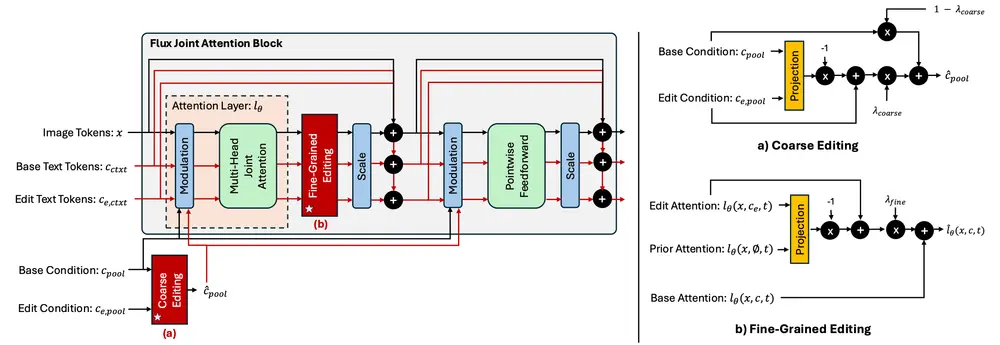
FluxSpace 在 Flux 的联合变换器块中引入了双层编辑方案,支持粗粒度和细粒度视觉编辑。具体来说:
- 粗粒度编辑:在基础(cpool)和编辑(ce, pool)条件的池化表示上操作,允许全局变化(如风格化),由尺度 λcoarse 控制。这种编辑方式适用于需要对整个图像进行大规模修改的任务,例如改变图像的整体风格或氛围。
- 细粒度编辑:定义了一种线性编辑方案,使用基础、先验和编辑注意力输出,由尺度 λcontext 引导。这种编辑方式适用于需要对图像中的特定区域进行精确修改的任务,例如添加眼镜或调整面部特征。
通过这种双层设计,FluxSpace 能够同时执行粗粒度和细粒度编辑,并具有线性可调的尺度,使得用户可以根据需求灵活调整编辑的强度和范围。
2. 语义可解释的注意力输出
FluxSpace 利用了校正流模型中变换器块学习到的注意力机制,提取出语义可解释的表示。这些表示不仅捕捉了图像中的全局结构信息,还能够识别和分离出图像中的局部特征。通过这种方式,FluxSpace 实现了对图像中不同部分的解耦编辑,确保在修改某些属性时不会影响其他无关的部分。
3. 基于文本引导的编辑
FluxSpace 支持基于文本引导的编辑,用户可以通过简单的关键词描述来指定所需的编辑内容。例如,用户可以输入“卡车”来将汽车转换为卡车,或者输入“太阳镜”来为人物添加太阳镜。这种基于文本的编辑方式使得用户可以轻松地对图像进行复杂的修改,而无需手动提供掩码或其他复杂的输入。
编辑结果
1. 不同概念的面部编辑
FluxSpace 能够执行从细粒度面部编辑(例如添加眼镜)到图像整体结构变化的多种编辑(例如漫画风格)。实验结果表明,该方法能够在保持图像整体一致性的同时,实现精确的局部修改。
2. 多主体编辑
除了仅有一个主体的图像编辑外,FluxSpace 还能够通过全局识别语义并同时编辑多个主体。例如,在包含多个人物的图像中,用户可以一次性对所有人物进行相同的编辑,而不会影响背景或其他无关部分。
3. 不同成像设置下的局部编辑
FluxSpace 能够执行导致局部变化的编辑,例如添加太阳镜。由于该方法利用了 Flux 的语义理解能力,因此可以在不同的成像设置下精确执行所需的编辑,确保编辑结果的一致性和自然性。
4. 不同成像设置下的全局编辑
FluxSpace 还能够执行导致全局外观变化的编辑。例如,在性别编辑等整体主体会发生显著变化的编辑中,该框架能够保留与编辑无关的细节,并充分调整目标主体,确保编辑后的图像仍然保持自然和逼真的效果。

© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











