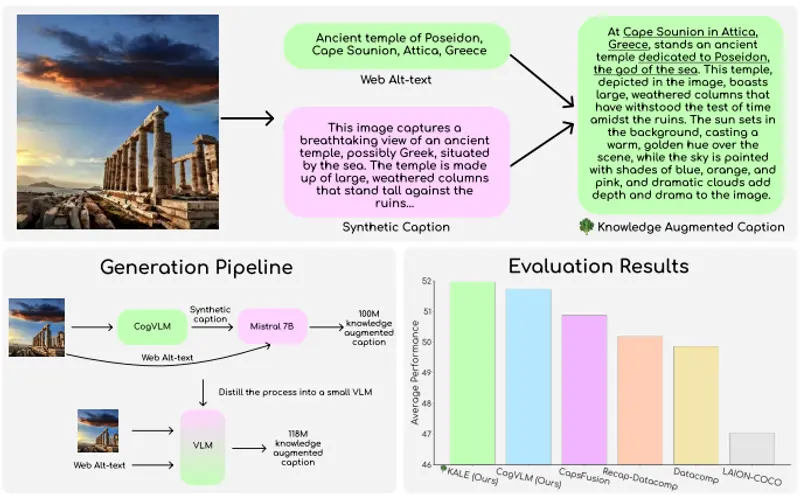
华盛顿大学、Salesforce Research、斯坦福大学和加州大学伯克利分校推出一个包含2.18亿个图像-文本对的数据集BLIP3-KALE,它弥合了描述性合成字幕和网络规模的事实性替代文本之间的差距。KALE通过将网络规模的替代文本与合成的密集图像字幕相结合,生成基于事实的图像字幕。
例如,考虑一张图片,图片中有一个红色的苹果放在桌子上。一个描述性的合成字幕可能会简单地说“一个红色的苹果”。但是,KALE通过结合网络规模的alt-text,可以生成一个更丰富的字幕,比如“一个鲜红色的苹果放在木质桌子上,可能是在户外市场上拍摄的”。
主要功能和特点
- 大规模和高密度:KALE包含2.18亿个图像-文本对,平均每个字幕有67.26个单词,是之前工作的1.82倍规模和近3倍密度。
- 知识增强:KALE的字幕不仅包含图像的描述,还融入了从网络alt-text中提取的现实世界知识。
- 高效的生成:通过将知识增强过程蒸馏到一个紧凑的2B参数字幕模型中,KALE能够以更低的成本生成与更大模型相当的高质量字幕。
- 两阶段方法:KALE采用了两阶段方法来生成和扩展数据集,首先创建一个知识增强的密集字幕的初始池,然后使用这些字幕来训练一个VLM,以实现数据集的扩展。
工作原理
KALE的工作原理涉及以下步骤:
- 第一阶段:使用CogVLM-17B生成Datacomp-1B图像的密集字幕,并使用语言模型Mistral增强这些字幕,添加相关的事实信息。
- 第二阶段:使用第一阶段生成的知识增强字幕来训练一个VLM,该VLM接受图像块嵌入和Datacomp-1B字幕作为输入,并输出知识增强的字幕。
- 去除流水线工件:识别并去除在生成字幕过程中从系统提示中泄露的文本。
具体应用场景
KALE数据集的应用场景包括:
- 多模态任务的性能提升:通过在KALE上训练VLM,可以在多种视觉-语言任务上提高模型性能,如视觉问答、科学问题回答等。
- 对话式AI的更新:KALE可以帮助改进对话式AI系统,使其能够更准确地理解和生成与图像相关的对话。
- 搜索引擎优化:KALE可以用于优化搜索引擎的响应机制,使其能够提供更丰富、更准确的图像搜索结果。
KALE的引入为构建更智能、知识更丰富的多模态模型提供了一个重要的工具,特别是在需要处理和理解大量图像和相关文本数据的应用中。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











