
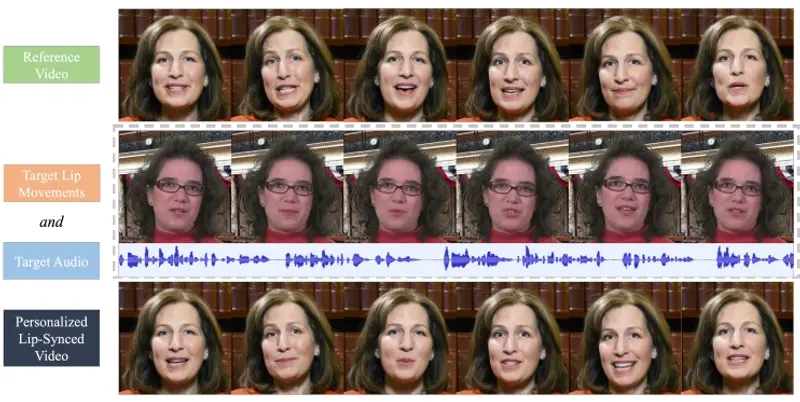
在音频驱动的视觉配音中,合成准确的口型同步同时保持和突出说话者的“个性”是一个巨大的挑战。现有方法往往未能捕捉到说话者的独特说话风格或保留面部细节。为了解决这一问题,字节跳动提出了 PersonaTalk,这是一个基于注意力的两阶段框架,旨在实现高保真和个性化的视觉配音。
PersonaTalk是一种用于视觉配音(Visual Dubbing)的先进框架。视觉配音是指将目标音频与参考视频(人物)结合起来,生成一个高保真度、个性化的唇形同步视频,同时突出说话者的个性,比如说话风格和面部细节。假设我们有一个视频,视频中的人物正在讲话,但我们希望将他们的语音替换成另一种语言或不同的声音,同时保持原有的唇形和面部表情。使用PersonaTalk技术,我们可以将目标音频(比如用另一种语言录制的音频)与原视频结合,生成一个新的视频,在新视频中,人物的唇形和面部表情与新的音频完全同步,就像他们原本就是用这种语言讲话一样。
主要功能
- 高保真度和个性化的视觉配音:能够生成与目标音频同步的唇形,同时保留说话者的独特风格和面部细节。
- 两阶段框架:包括几何构建和面部渲染,以实现高质量的视觉配音。
- 风格感知音频编码:通过交叉注意力层将说话风格注入音频特征。
- 双注意力面部渲染器:分别对唇部和面部其他区域的纹理进行采样,以生成具有复杂面部细节的逼真图像。
主要特点
- 风格感知:能够捕捉和再现说话者的独特说话风格。
- 双注意力机制:分别对唇部和面部进行纹理采样,以保留更多的面部细节。
- 无需特定人物训练:作为一个通用框架,不需要针对特定人物进行训练或微调即可达到与特定人物方法相媲美的性能。
工作原理
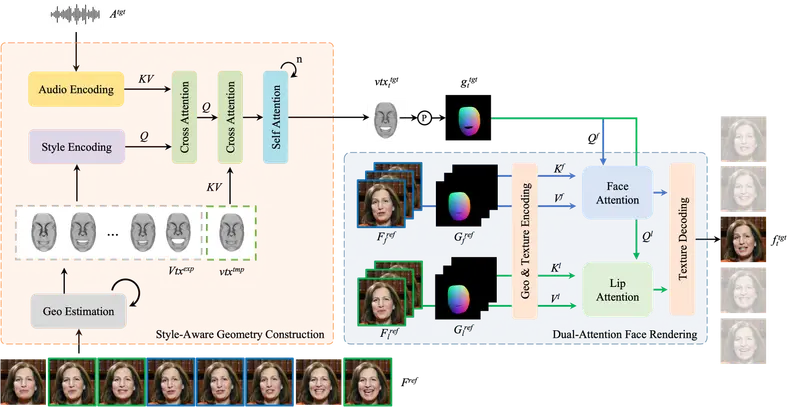
PersonaTalk 包括两个主要阶段:几何构建和面部渲染。这两个阶段通过创新的设计,确保了口型同步的准确性以及说话者个性的保留。
- 几何构建阶段:首先,使用混合几何估计方法提取说话者的3D面部几何信息。然后,通过交叉注意力层将风格信息注入音频特征,并使用这些特征驱动模板几何以获得与音频同步的唇形几何。
- 面部渲染阶段:在这一阶段,使用双注意力面部渲染器来渲染目标几何的纹理。这个渲染器包含两个并行的交叉注意力层:Lip-Attention和Face-Attention。Lip-Attention从唇部参考帧中采样唇部相关纹理,而Face-Attention从面部参考帧中采样其他面部纹理。
第一阶段:几何构建
风格感知的音频编码模块:
- 交叉注意力层:通过交叉注意力层将说话者的风格注入音频特征中。这一模块能够捕捉到说话者的独特声音特征,如语速、音调和节奏。
- 风格化音频特征:生成的风格化音频特征不仅包含了音频信息,还融入了说话者的个性化风格。
驱动模板几何:
- 口型同步几何形状:使用风格化的音频特征驱动说话者的模板几何,生成与音频同步的口型几何形状。这一过程确保了口型同步的准确性。
第二阶段:面部渲染
双注意力面部渲染器:
- 唇部注意力:通过唇部注意力层从参考帧中采样唇部纹理,确保唇部细节的高保真度。
- 面部注意力:通过面部注意力层从参考帧中采样整个面部的纹理,确保面部其他部分的细节也得以保留。
纹理渲染:
- 综合纹理:双注意力机制从不同的参考帧中采样纹理,综合渲染出整个面部的高保真纹理。这一过程确保了面部细节的复杂性和自然性。
创新设计
- 风格感知的音频编码:通过交叉注意力层将说话者的风格注入音频特征中,确保了音频特征的个性化。
- 双注意力面部渲染:唇部注意力和面部注意力分别处理唇部和面部的纹理,确保了面部细节的高保真度。
具体应用场景
- 多语言视频内容制作:将视频内容翻译成不同语言,同时保持原始视频中人物的唇形和表情。
- 视频编辑和后期制作:在电影或电视剧的后期制作中,用于修改人物对话或配音。
- 虚拟主播和数字人:为新闻播报、在线教育或娱乐内容创建虚拟人物,使其能够以自然的方式“说话”。
- 交互式媒体:在游戏中,根据玩家的语音指令,实时生成角色的唇形和面部表情。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











