
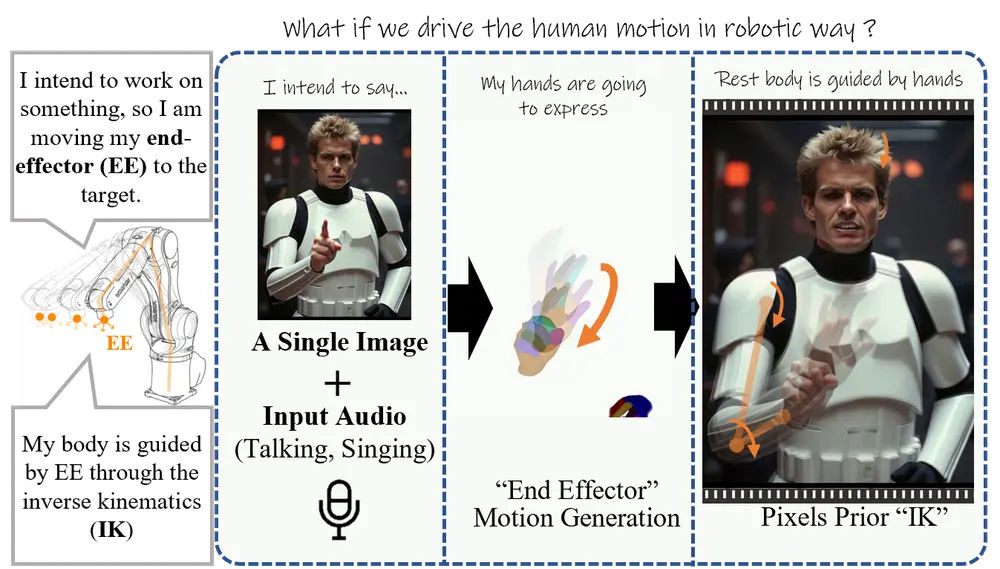
阿里在去年2月推出新型音频驱动的虚拟角色视频生成方法EMO,近期又发布了 EMO2,它能够同时生成富有表现力的面部表情和手势动作。该方法特别关注于语音伴随手势(co-speech gestures)的生成,通过重新定义任务为两阶段流程,解决了现有方法在生成全身或半身姿态时存在的音频与全身姿态对应关系较弱的问题。EMO2 通过生成与音频高度同步的手部动作,并将其融入视频帧合成中,生成自然且富有表现力的虚拟角色视频。
例如,有一个虚拟主播需要根据输入的语音生成相应的动作和表情。使用 EMO2 方法,当输入一段演讲语音时,系统首先根据语音生成与之匹配的手部动作(如手势、挥手等),然后利用这些手部动作作为引导信号,生成包含面部表情和身体动作的完整视频。最终生成的视频不仅手部动作自然,面部表情丰富,而且整体动作与语音高度同步。
主要功能
- 生成自然的手势动作:能够根据输入的语音生成与之高度相关的手部动作。
- 生成富有表现力的面部表情:结合手部动作生成自然且富有表现力的面部表情。
- 同步音频与动作:确保生成的视频中动作与音频在时间上高度同步。
- 支持多样化风格:通过风格嵌入,可以生成不同风格(如演讲、唱歌、舞蹈等)的动作。
主要特点
- 两阶段生成框架:将任务分为两个阶段,先生成手部动作,再生成视频帧,简化了问题的复杂性。
- 利用手部动作作为“末端执行器”:借鉴机器人控制中的“末端执行器”概念,通过手部动作引导全身动作,利用视频生成模型的像素级先验知识解决逆运动学问题。
- 高同步性和自然性:生成的视频在视觉质量和同步精度上优于现有方法,动作更加自然流畅。
- 灵活性和多样性:通过调整风格嵌入和速度嵌入,可以生成不同风格和速度的动作,增加了动作的多样性和灵活性。
工作原理
第一阶段:手部动作生成:
- 输入音频信号,利用基于扩散模型的 DiT(Diffusion Transformer) 结构,通过自注意力和交叉注意力机制,生成与音频同步的手部动作。
- 通过手部动作的生成,作为后续视频生成的控制信号。
第二阶段:视频帧合成:
- 使用 ReferenceNet 结构,结合参考图像和第一阶段生成的手部动作,生成完整的视频帧。
- 通过扩散模型的去噪过程,将音频特征、手部动作特征和参考图像特征融合,生成自然且富有表现力的视频。
关键模块:
- 手部动作控制:通过手部动作引导全身动作,利用视频生成模型的像素级先验知识解决逆运动学问题。
- 音频驱动:通过音频特征与生成模型的融合,确保视频中的动作与音频高度同步。
- 风格和速度嵌入:通过风格嵌入和速度嵌入,可以生成不同风格和速度的动作,增加动作的多样性和灵活性。
具体应用场景
- 虚拟主播:为虚拟主播生成自然且富有表现力的动作和表情,提升观众的观看体验。
- 动画制作:快速生成动画角色的动作和表情,降低动画制作成本,提高制作效率。
- 游戏开发:为游戏角色生成与语音同步的动作和表情,增强游戏的沉浸感。
- 教育和培训:生成教育视频中的虚拟教师动作和表情,提高教学效果。
- 娱乐应用:为音乐视频、短剧等生成与音频同步的虚拟角色表演,丰富娱乐内容。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











