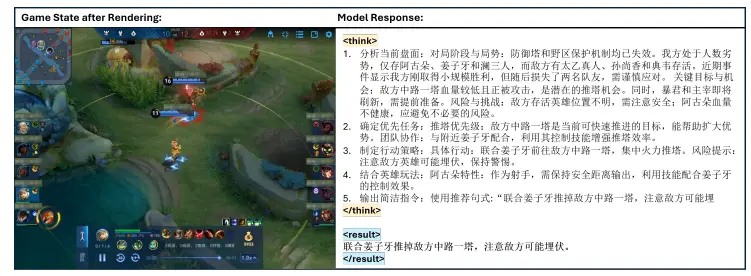
来自卡内基梅隆大学、伊利诺伊大学香槟分校和丰田研究所的研究者们共同提出了一种名为ReferEverything(Reference Expression Modeling)的创新框架,专为视频中通过自然语言描述的概念进行分割而设计。这一技术的发展不仅拓宽了视频处理的应用范围,还为自然语言与视觉信息之间的交互开辟了新的路径。REM框架能够处理如“窗户中心流淌的雨滴”或“香烟消散的烟雾”这样的动态瞬间,以及“玻璃破碎”或“水中形成漩涡”等动态过程。这些例子展示了REM框架能够理解和定位视频中的复杂和动态的视觉内容。

主要特点:
- 广泛的适用性:能够处理罕见和未见过的物体,以及非物体的动态概念,如海浪冲击。
- 强大的泛化能力:尽管只在有限类别的对象掩码上训练,但能够泛化到非物体的动态概念。
- 利用互联网规模预训练:通过在大规模视频-语言数据集上预训练,REM能够捕捉丰富的视觉-语言空间表示。
REM的工作原理
REM的核心在于其利用互联网规模的数据集来训练视频扩散模型,从而获得强大的视觉-语言表示能力。这种方法的关键在于保持生成模型原有的表示能力,同时针对特定领域的引用对象分割任务进行微调。这意味着,即使REM框架是在有限种类的对象掩码上训练的,它依然能够精确地识别并追踪视频中罕见或从未见过的对象。
基于以下几个步骤:
- 视频去噪:使用预训练的变分自编码器(VAE)将视频从像素空间映射到潜在空间,并在潜在空间中进行去噪。
- 条件去噪:在去噪过程中,模型通过交叉注意力机制将文本条件与潜在表示相结合,生成与文本描述相符的视频。
- 分割掩码预测:在微调阶段,模型的输出从预测高斯噪声调整为预测分割掩码,从而实现视频中特定区域的分割。
扩展至非对象动态概念
除了传统的对象分割任务,REM还展示了其在处理非对象动态概念方面的潜力,比如海浪拍打等自然现象。这得益于模型强大的泛化能力,使其能够适应和理解更为复杂和抽象的视觉内容。
引入RefVPS基准测试
为了验证REM的效果,研究团队还引入了一个全新的基准测试——引用视频过程分割(RefVPS)。在这一测试中,REM不仅能够在标准数据集(如Ref-DAVIS)上达到与现有最佳方法相匹敌的性能,而且在处理域外数据时,还能展现出显著的优势。特别是在区域相似度方面,REM的表现最高可超出其他方法12个百分点。
实验结果与展望
实验结果显示,REM在处理特定领域内的视频数据时,能够达到行业领先的水平;而在面对未知或跨领域的挑战时,凭借其强大的预训练背景,REM同样能够提供令人满意的结果。这一成就不仅证明了REM框架的有效性,也为未来在视频分析、人机交互等领域中的应用提供了广阔的空间。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











