
来自南开大学和字节跳动的研究人员推出一种新的图像和视频生成框架StoryDiffusion,这项技术的核心在于它能够生成一系列内容一致的图像和视频,这对于讲述一个故事或者展示一个连贯的场景来说非常重要。下面我将用易于理解的语言来介绍这项技术的主要功能、特点、工作原理以及可能的应用场景。
- 项目主页:https://storydiffusion.github.io
- GitHub:https://github.com/HVision-NKU/StoryDiffusion
- Demo:https://huggingface.co/spaces/YupengZhou/StoryDiffusion
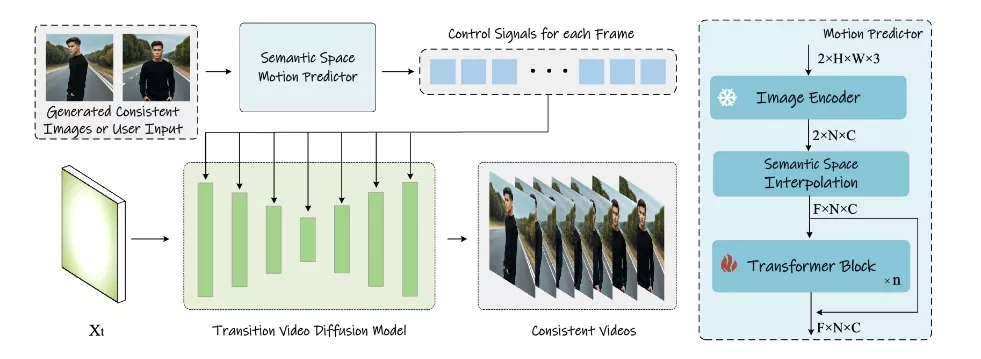
开发人员提出了一种新的自注意力计算方法,名为“一致自注意力”,该方法显著提升了生成图像之间的一致性,并以零次学习的方式增强了流行的基于预训练的扩散文本到图像模型。为了将StoryDiffusion扩展到长视频生成,开发人员进一步引入了一个新颖的语义空间时间运动预测模块,即“语义运动预测器”。该模块被训练用来估计在语义空间中两个给定图像之间的运动条件。此模块能够将生成的图像序列转换为视频,这些视频具有平滑的过渡和一致的主体,其稳定性明显优于仅基于潜在空间的模块,特别是在长视频生成的背景下。

例如,你要制作一个关于“丛林冒险”的漫画系列,你可以用StoryDiffusion来生成一系列图像,其中的主角在不同的场景中保持一致的外观,比如同样的服装和面孔。然后,这些图像可以被转换成视频,形成一个连贯的动画故事。这就是StoryDiffusion技术的神奇之处,它能够让你以一种非常直观和高效的方式讲述视觉故事。
主要功能:
StoryDiffusion 的主要功能是生成具有一致性的图像序列和视频。这意味着,无论你要求它生成多少张图片或者多长的视频,里面的人物、服装和其他细节都能保持一致,就像是一个连贯的故事。
主要特点:
- 一致性:StoryDiffusion 能够保证生成的图像中的人物身份和服装的一致性,这对于讲述一个视觉故事至关重要。
- 无需训练:它的一个创新之处在于,即使没有经过专门的训练,也能即插即用地提高现有图像生成模型的性能。
- 长距离视频生成:StoryDiffusion 还能够生成长距离的视频,这在以往的技术中是一个挑战。

工作原理:
StoryDiffusion 的工作原理可以分为两个阶段:
- 图像生成阶段:它使用一种称为“Consistent Self-Attention”的技术来生成一致的图像。这种技术通过在生成过程中建立图像之间的联系,使得一批图像能够共享相同的人物特征,如面孔和服装。
- 视频生成阶段:在生成了一系列一致的图像之后,StoryDiffusion 通过一个名为“Semantic Motion Predictor”的模块将这些图像转换成视频。这个模块能够预测两张图像之间的过渡动作,并生成平滑的视频帧。
具体应用场景:
- 故事讲述:可以用它来生成一系列讲述特定故事的图像或视频。
- 电影制作:在电影的前期制作中,可以用来生成场景的概念图或者动画草图。
- 游戏开发:在游戏设计中,可以用来快速生成游戏角色的不同造型或者动画。
- 广告和营销:可以用于生成引人注目的广告图像或视频,以吸引潜在客户的注意。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











