来自MIT、浙江大学、清华大学、MIT-IBM Watson AI实验室的研究人员推出新型视觉模型EfficientViT,它专门用于高分辨率的密集预测任务。这类任务在计算机视觉领域非常重要,应用范围广泛,包括计算摄影、自动驾驶、医学图像处理等。简单来说,EfficientViT的目标是在保持高准确度的同时,显著提高模型在各种硬件设备上的运行速度,使其更适合实际应用。EfficientViT是一个在保持高准确度的同时,显著提高了计算效率的视觉模型,特别适合需要实时处理和在资源受限的硬件设备上运行的高分辨率密集预测任务。
主要功能和特点:
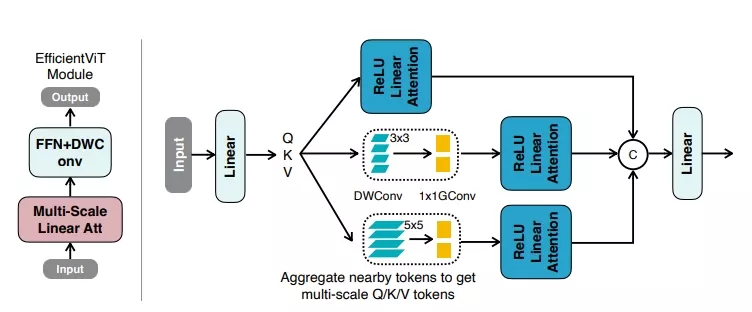
- 多尺度线性注意力机制:EfficientViT的核心是一种新颖的多尺度线性注意力模块,它能够在保持硬件高效运算的同时,实现全局感知野和多尺度学习。
- 轻量级和硬件友好:与以往的模型相比,EfficientViT避免了那些在硬件上运行效率低下的操作,如高计算复杂度的softmax注意力机制或大卷积核。
- 显著的性能提升:EfficientViT在不同的硬件平台上,包括移动CPU、边缘GPU和云GPU,相比之前的最先进模型,都实现了显著的性能提升和速度加快。
- 保持或提升准确度:在Cityscapes等数据集上,EfficientViT在减少GPU延迟的同时,并没有牺牲准确度。
工作原理:
EfficientViT通过以下几个关键步骤实现其功能:
- 全局感知野:通过使用ReLU线性注意力机制替代传统的softmax注意力,EfficientViT能够在计算复杂度较低的情况下捕获输入图像的全局信息。
- 多尺度学习:通过小卷积核聚合附近的特征,生成多尺度的特征表示,然后对这些特征进行线性注意力操作,以结合全局感知野和多尺度学习。
- 深度可分离卷积:在前馈网络(FFN)层中插入深度可分离卷积,以增强局部特征的提取能力。
具体应用场景:
- 自动驾驶:在自动驾驶系统中,EfficientViT可以用来进行精确的语义分割,识别道路、车辆、行人等,以做出安全的驾驶决策。
- 医学图像处理:在医学图像分析中,EfficientViT可以帮助进行像素级别的分类,比如区分健康组织和病变区域。
- 计算摄影:在计算摄影中,EfficientViT可以用于图像的超分辨率重建,提高图像的分辨率而不失细节。
- 通用图像分割:EfficientViT还可以用于“Segment Anything”任务,这是一种允许零样本迁移到许多视觉任务的提示型分割任务。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











