
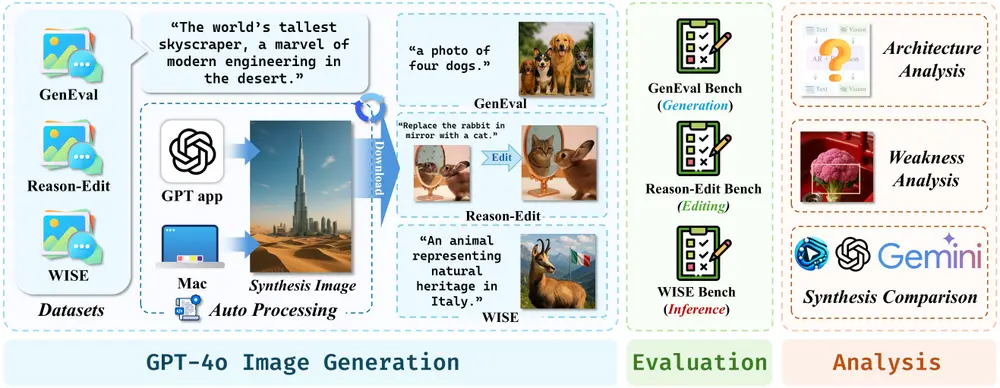
北京大学深圳研究生院、中山大学、Rabbitpre AI、上海人工智能实验室、深圳大学和香港科技大学(广州)的研究人员发布首个针对 GPT-4o 图像生成能力进行定量和定性评估的基准测试GPT-ImgEval,用于评估 OpenAI 的 GPT-4o 模型在图像生成和编辑任务中的性能。
GPT-4o 是一种多模态大语言模型(MLLM),在图像生成、编辑和视觉语言推理方面表现出色。GPT-ImgEval 通过三个关键维度对 GPT-4o 的性能进行量化和定性评估:
- 图像生成质量(GenEval)
- 图像编辑(Reason-Edit)
- 基于世界知识的语义生成(WISE)
研究团队的全面结果显示,GPT-4o 在图像生成和理解能力上显著优于之前的模型。
生成架构分析
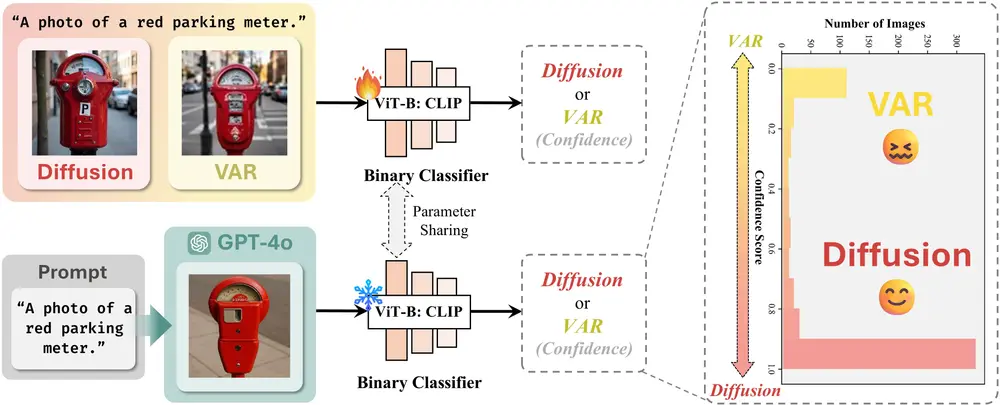
基于基准测试结果,研究团队深入分析了 GPT-4o 可能的底层架构。通过基于分类器的图像分析,研究团队确认其解码器很可能是基于扩散(Diffusion)架构,并推测了可能的编码器范式。
更详细的分析
研究团队提供了对 GPT-4o 生成结果的详细分析,并系统研究了其弱点,包括常见的失败模式和生成伪影。此外,研究团队比较了 GPT-4o 与 Gemini 2.0 Flash 在多轮图像编辑能力上的表现。同时,研究团队探讨了 AIGC 安全问题,通过现有最先进的图像取证模型评估 GPT-4o 生成图像的可检测性。
数据集下载
研究团队已上传了 Reason-Edit 和 GenEval 数据集的 GPT 生成结果。研究团队还将在未来两天内上传自动化脚本,以帮助更多人评估 GPT-4o 的图像合成能力。
评估结果
根据表格数据,GPT-4o 获得最高的综合得分 0.84,远超冻结文本编码器方法和基于 LLM/MLLM 增强的方法。
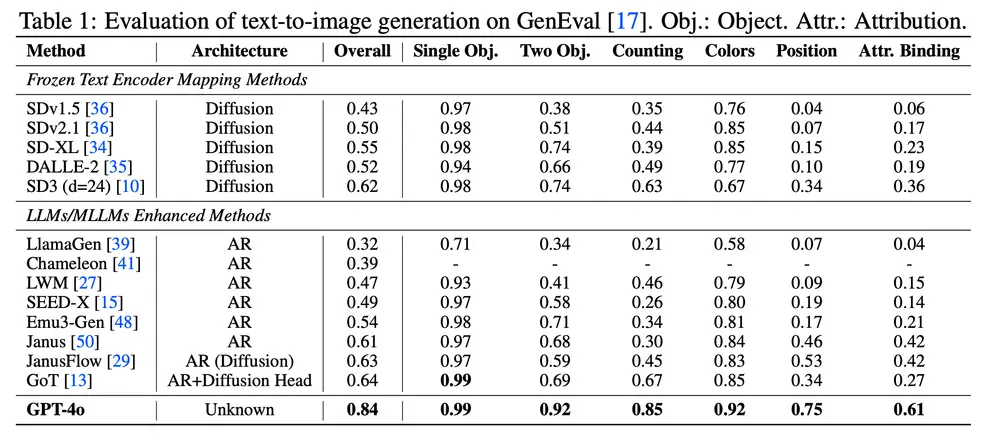
图表展示了 GPT-4o 在 GenEval 基准中六个核心评估类别的组合式文本到图像生成能力的定性示例。

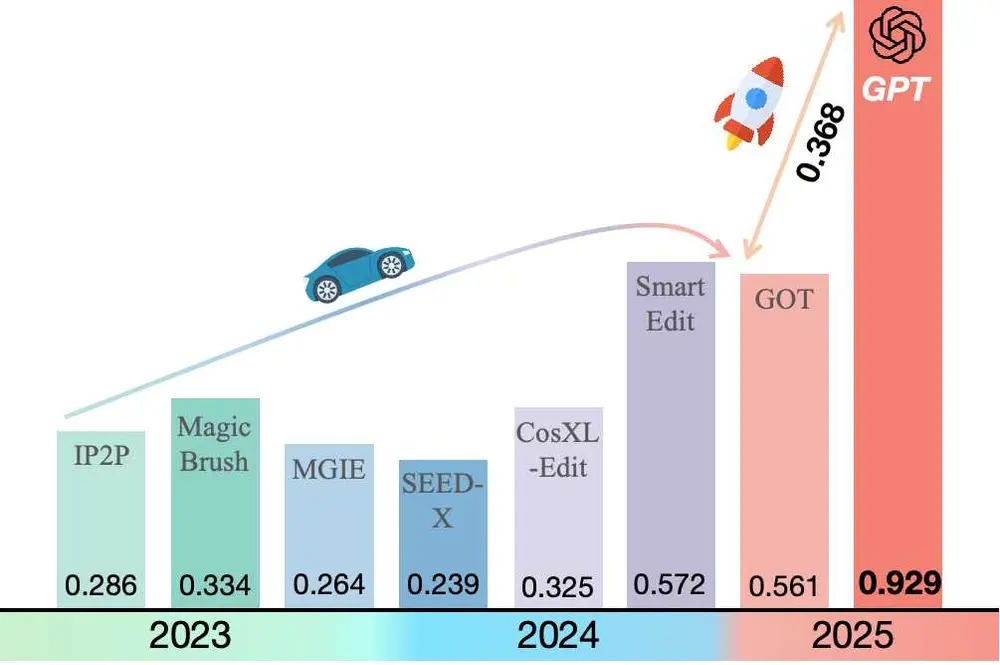
如柱状图所示,GPT-4o 在 Reason-Edit 基准中显著优于所有现有图像编辑方法,得分高达 0.929。这比 2025 年之前的最佳方法(SmartEdit,得分 0.572)提高了惊人的 +0.357,凸显了模型强大的指令跟随能力和细粒度编辑控制。
GPT-4o 在总体 WiScore 上显著优于现有的专门 T2I 生成方法和统一的 MLLM 基础方法。GPT-4o 结合了卓越的世界知识理解和高保真图像生成,在多模态生成任务中展现出双重优势。
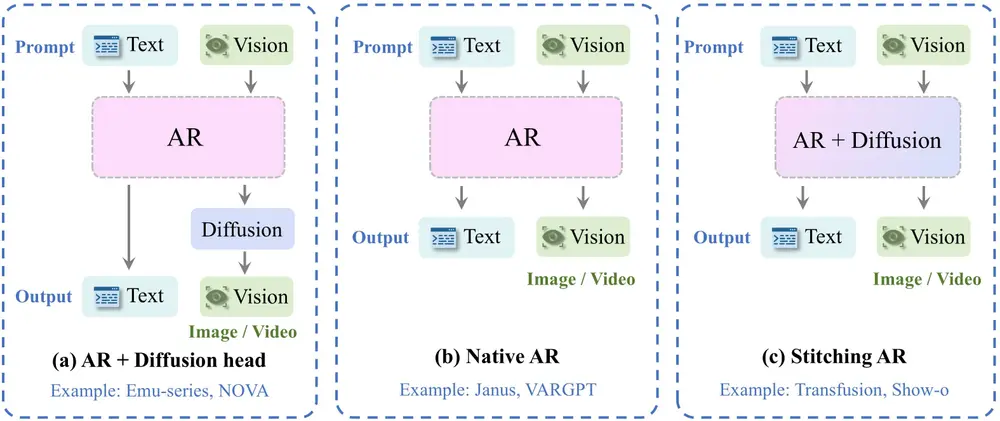
生成架构
除了基准评估外,研究团队进行了更深入的分析,以揭示 GPT-4o 可能的架构选择。具体来说,研究团队首先探讨 GPT-4o 是依赖基于扩散的解码器还是自回归解码器。为此,研究团队提出了一种基于模型的分类方法,训练一个标准二元分类器来区分两种范式生成的图像,然后将其应用于 GPT-4o 的输出。有趣的是,分类器始终将 GPT-4o 的图像归类为基于扩散的图像,这提供了经验证据,表明 GPT-4o 可能在内部使用扩散头进行图像解码。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











