
来自香港中文大学、Avolution AI、上海人工智能实验室、商汤科技研究院的研究人员推出快速视频生成方法AnimateLCM,该方法利用一致性学习策略,将图像生成先验和运动生成先验进行解耦,从而提高训练效率和生成质量。这个系统特别关注于提高视频生成的速度和质量,同时减少计算资源的消耗。
此外,为了能够结合稳定扩散社区中的即插即用适配器来实现各种功能(例如,使用ControlNet进行可控制的视频生成),我们还提出了一种高效的策略,既可以将现有的适配器调整到我们的文本条件视频一致性模型中,也可以从零开始训练适配器,而这一切都不会影响采样速度。
主要功能和特点:
- 加速视频生成:AnimateLCM通过一种称为“解耦一致性学习”的策略,能够在较少的步骤内生成高质量的视频,这比传统的扩散模型要快得多。
- 个性化风格:系统允许用户通过替换模型的权重来实现不同风格(如现实主义、2D动画、3D动画)的视频生成。
- 无需特定教师模型:AnimateLCM提出了一种无需特定教师模型的适配器训练策略,这使得现有的适配器能够更好地适应视频生成任务,或者从头开始训练新的适配器。
工作原理:
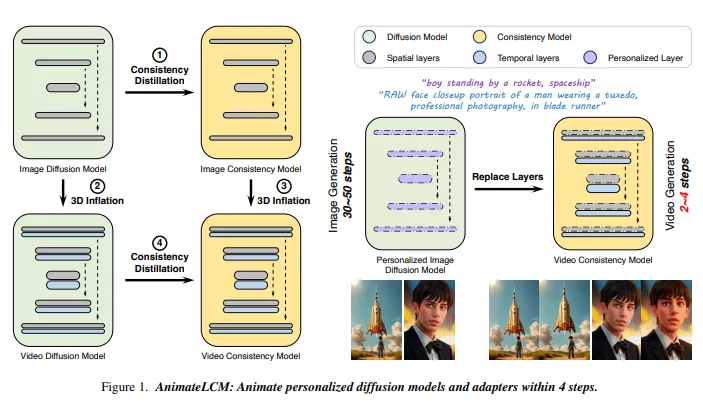
AnimateLCM的核心思想是将视频生成任务分解为图像生成和运动生成两个部分:
首先,它在高质量的图像数据集上训练图像一致性模型,然后通过3D膨胀(3D Inflation)将这些模型扩展到视频领域。
接着,系统在视频数据上进行一致性蒸馏,以获得最终的视频一致性模型。为了提高训练效率,AnimateLCM采用了一种特殊的初始化策略,通过指数移动平均(EMA)逐渐将空间LoRA权重合并到目标一致性模型中。
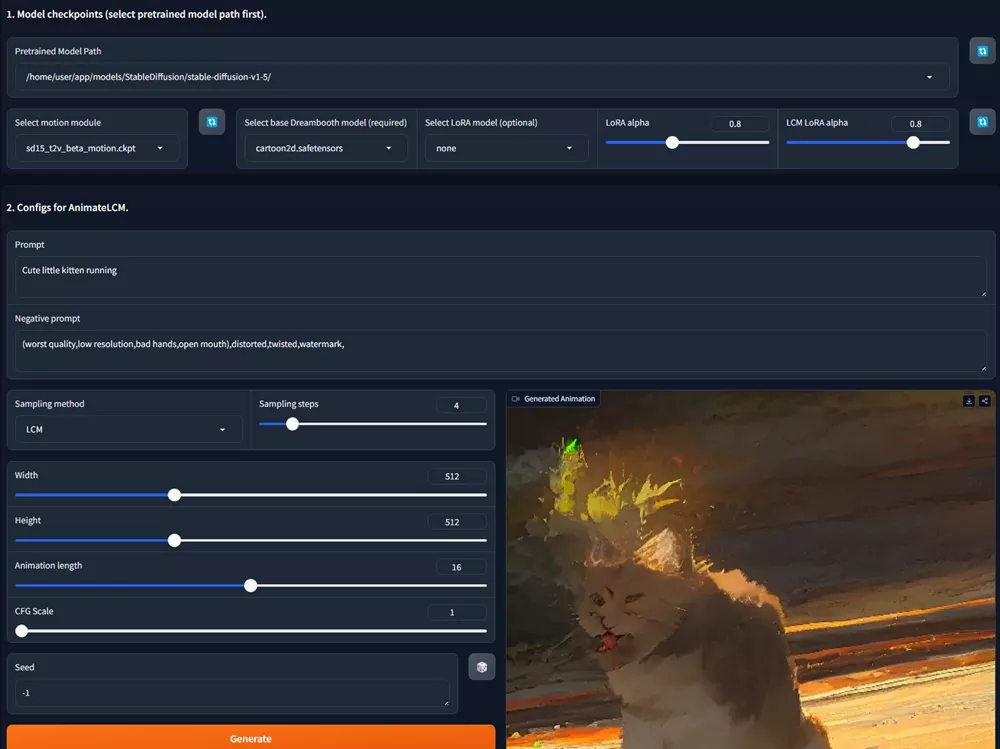
AnimateLCM通过其高效的视频生成能力和对个性化风格的支持,为视频内容创作提供了一个强大的工具,特别是在需要快速迭代和多样化风格输出的场景中。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











