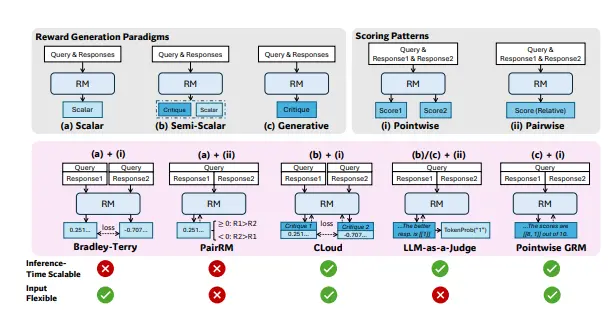
稀疏自编码器(SAEs)已成为逆向工程大语言模型(LLMs)的核心组成部分。SAEs通过将中间表示分解为可解释特征的稀疏和,促进了对模型内部机制的更好理解和控制。然而,类似的分析和方法在文本到图像模型中一直缺乏。洛桑联邦理工学院的研究人员最近的一项研究填补了这一空白,使用稀疏自编码器(Sparse Autoencoders, SAEs)来解释和理解文本到图像模型,特别是SDXL Turbo模型的内部工作机制。这项研究的核心目标是揭示大语言模型(LLMs)在文本到图像生成过程中的中间表示,并尝试将这些难以直接解释的表示分解为可解释的特征,以便更好地控制和分析模型的生成过程。
- GitHub:https://github.com/surkovv/sdxl-unbox
- Demo:https://huggingface.co/spaces/surokpro2/Unboxing_SDXL_with_SAEs
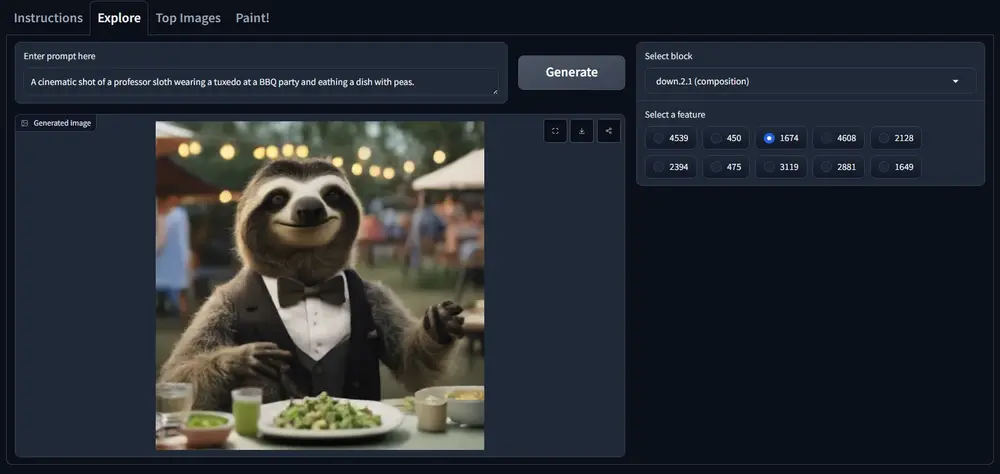
我们有一个文本到图像的生成任务,用户输入了文本提示“一个穿着燕尾服的教授树懒在烧烤派对上的电影镜头”。SDXL Turbo模型能够根据这个提示生成相应的图像。但是,我们并不了解模型是如何理解这个提示并将其转化为图像的。通过使用稀疏自编码器,我们可以分解模型的中间表示,识别出哪些特征与文本提示中的特定元素(如“树懒”、“燕尾服”、“烧烤派对”)相关联,从而更好地理解模型的生成逻辑。

主要功能:
特征分解:将模型的中间表示分解为稀疏的特征和,使得这些特征可以被解释和理解。 生成过程控制:通过识别影响生成过程的关键特征,可以对模型的输出进行更精细的控制。 模型分析:分析模型的内部工作机制,揭示不同模块在图像生成中的具体作用。
主要特点:
无需额外数据或模型:使用SAEs不需要额外的数据或专有模型,完全依赖于模型自身的知识和技能。 迭代训练框架:通过交替训练生成器(Generator)和扩展器(Extender),逐步增加模型输出的长度和复杂性。 特征的可解释性:学习到的特征具有较高的可解释性,可以通过可视化技术进行分析。
工作原理:
稀疏表示:通过SAEs将模型的中间表示近似为稀疏的特征和,其中每个特征都是一个向量。 特征学习:在训练过程中,SAEs学习到的特征能够捕捉到输入数据的重要特征。 特征重组:通过重组这些特征,可以重构出模型的中间表示,从而理解模型是如何根据输入生成输出的。
研究方法
SDXL Turbo:研究选择了SDXL Turbo作为目标模型,这是一种高效的文本到图像生成模型。
去噪U-net:在SDXL Turbo的去噪U-net中训练SAEs,以执行由transformer块进行的更新。 特征学习:SAEs被训练以学习可解释的特征,这些特征能够捕捉生成过程中的关键信息。
研究结果
特征分解:SAEs学习的特征是可解释的,能够将复杂的中间表示分解为有意义的特征。 因果影响:这些特征在生成过程中具有因果影响,能够直接影响生成的图像。
图像构图:研究发现,一个transformer块主要处理图像构图,负责生成图像的整体布局和结构。 局部细节:另一个块主要负责添加局部细节,如纹理和细小的图案。 颜色、光照和风格:还有一个块专门负责颜色、光照和风格的处理,确保生成的图像在视觉上一致且美观。
意义和影响
内部结构:这项工作是更好地理解像SDXL Turbo这样的生成文本到图像模型的内部结构的重要第一步。 特征可视化:通过SAEs学习的特征,可以可视化和分析模型在生成过程中的各个阶段的行为。
特征操控:可解释特征的发现使得在生成过程中对特定特征进行操控成为可能,从而提高生成图像的可控性和质量。 任务特定优化:可以根据任务需求对特定的transformer块进行优化,提高模型在特定任务上的性能。
创意设计:在创意设计领域,SAEs学习的特征可以帮助设计师更好地理解和控制生成过程,创造出更具创意和个性化的图像。 艺术生成:艺术家可以利用这些特征生成具有特定风格和主题的艺术作品。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











