商汤科技研究院、北京航空航天大学、莫纳什大学和香港科技大学推出一种用于加速DiT模型的训练和推理过程的方法HarmoniCa,通过基于Step-Wise去噪训练(SDT)和图像错误代理引导目标(IEPO)构建的新型基于学习的缓存框架,实现了训练和推理的和谐。与传统的训练范式相比,新提出的SDT保持了去噪过程的连续性,使模型能够在训练过程中利用先前时间步的信息,类似于它在推理过程中操作的方式。此外,研究人员设计了IEPO,它整合了一个高效的代理机制来近似由重用缓存特征引起的最终图像错误。因此,IEPO有助于平衡最终图像质量和缓存利用,解决了仅考虑每个时间步中缓存使用对预测输出的影响的训练问题。
例如,你是一个数字艺术家,想要创作一幅高分辨率的奇幻风景画。使用传统的扩散变换器可能需要很长时间来生成这样的图像,因为它需要进行很多计算步骤。但是,有了HarmoniCa,这个过程可以显著加速,让你更快地看到最终作品,甚至在生成过程中节省计算资源。

主要功能:
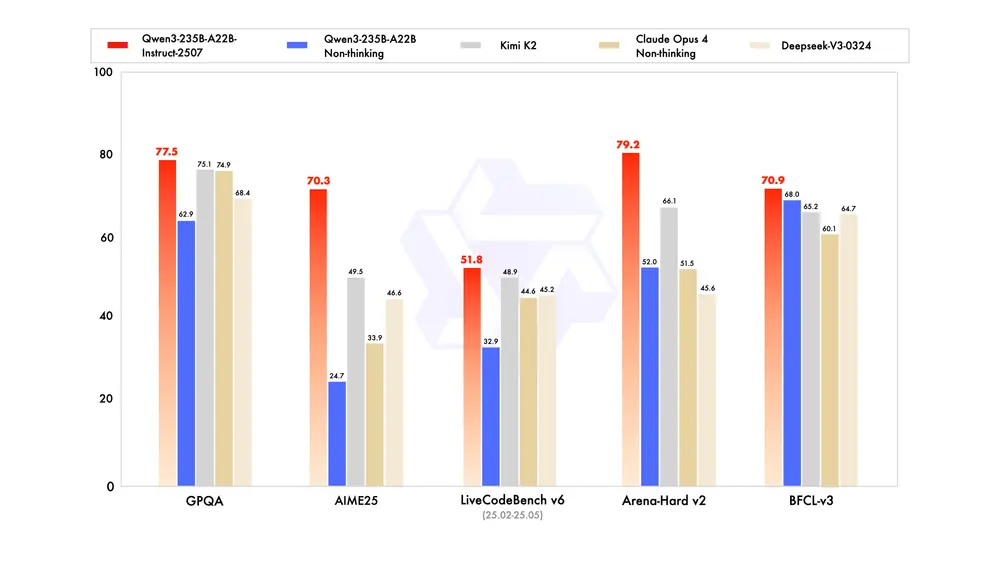
HarmoniCa的主要功能是减少扩散变换器(DiTs)在生成图片时所需的计算步骤,从而加快生成速度。
主要特点:
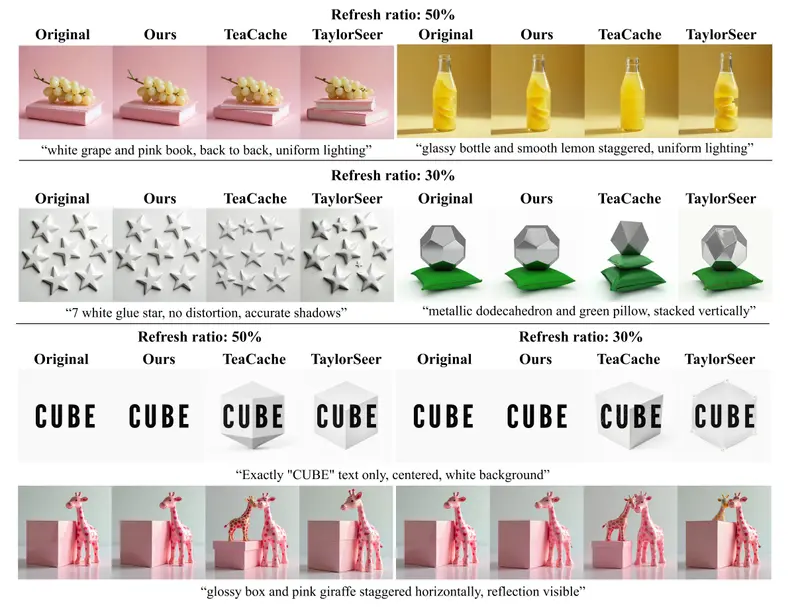
- 特征缓存机制:它通过存储和重用时间步之间的冗余计算来减少每一步的推理时间。
- 学习基础方法:它使用一种基于学习的方法来优化缓存策略,而不是手动设计。
- 训练与推理的一致性:解决了训练目标和推理目标之间的不一致性,提高了性能和加速比。
工作原理:
HarmoniCa通过两个主要的技术创新来工作:
- 逐步去噪训练(Step-Wise Denoising Training, SDT):这种方法在训练过程中模拟了完整的去噪轨迹,确保模型能够学习到早期时间步对当前步骤的影响。
- 图像误差代理引导目标(Image Error Proxy-Guided Objective, IEPO):它使用一个代理来近似最终图像误差,帮助在训练时平衡缓存使用和图像质量。
具体应用场景:
- 高质量图像生成:比如在在线平台或游戏中生成逼真的图像。
- 文本到图像的生成:根据文本描述生成相应的图片,比如在内容创作或者教育软件中。
- 视频生成:生成视频内容,比如在电影制作或者虚拟现实中。
总的来说,HarmoniCa通过优化扩散变换器的缓存策略,提高了生成图像的效率和质量,使得这些模型更适用于实际应用中。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...