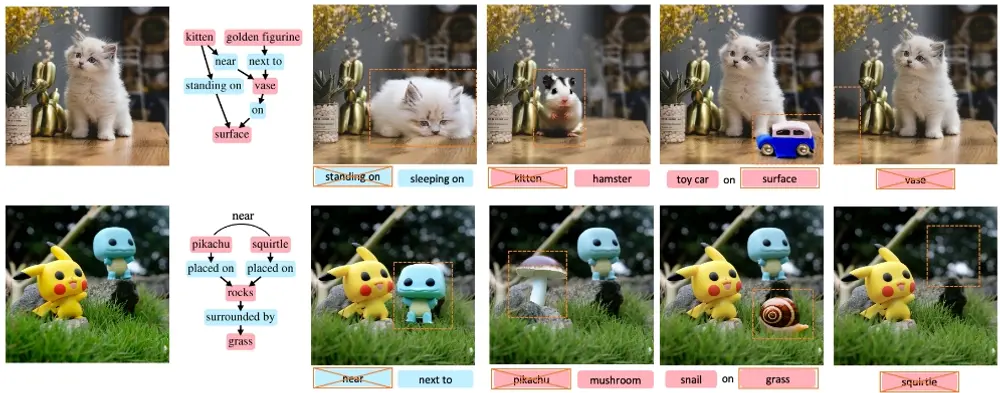
场景图提供了一种结构化、层次化的图像表示方式,其中节点和边分别代表图像中的对象及其相互关系。这种方式不仅能够帮助用户更直观地理解图像内容,还能作为图像编辑的有效接口,极大提升了编辑工作的准确性和灵活性。
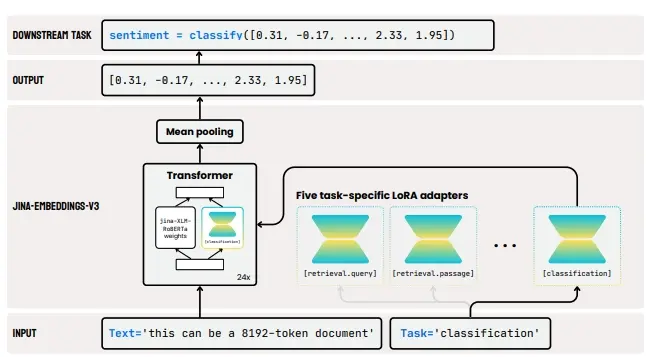
为了充分利用场景图的优势,来自香港城市大学和微软GenAI的研究团队共同开发了一种创新框架SGEdit,该框架成功地将大语言模型(LLM)与基于场景图的文本到图像生成模型结合在一起,用于基于场景图的精确和灵活的图像编辑。此框架的核心价值在于它能够在保持图像整体质量的前提下,实现对单个对象的精确编辑和对整个场景的创造性重组。
特点:
- 使用场景图作为图像编辑的自然接口
- 将 LLMs 与文本到图像生成模型集成,用于精确的对象级别修改
- 涉及两个阶段:场景解析和图像编辑
- 利用 LLM 驱动的场景解析器构建详细的场景图
- 使用注意力调制的扩散编辑器实现编辑
- 在编辑精度和场景美学方面优于现有的图像编辑方法
- 支持各种编辑任务,如改变关系、替换、添加和删除元素
- 允许用户在保持图像完整性的同时探索多样化的组合
框架的工作原理
本框架的工作流程主要分为两大步骤:
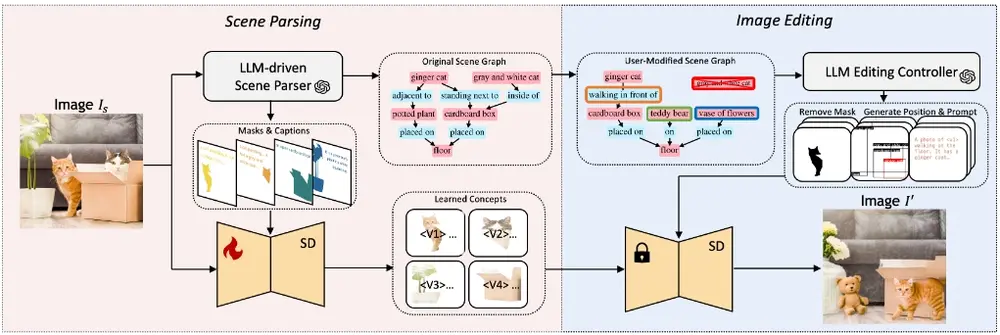
1. 场景图构建
首先,通过一个由LLM驱动的场景解析器来分析输入图像,构建出反映图像中关键对象及其关系的场景图。此外,解析器还会提取对象的细粒度属性,例如对象的轮廓和详细描述。这些信息将被用于训练经过微调的扩散模型,以增强其对不同概念的理解能力。每个对象都将通过一个优化后的Token和具体的描述提示来表示,从而确保模型能够准确捕捉到对象的特征。
2. 图像编辑
接下来,在图像编辑阶段,LLM编辑控制器负责指导对特定区域的修改工作。具体来说,这些编辑任务由一个注意力调制的扩散编辑器完成,后者利用经过微调的模型来实现对象的添加、移除、替换或调整等操作。这一过程不仅保证了编辑结果的精确性,也维护了图像原有的美感和完整性。
实验验证
通过一系列广泛的实验测试,研究团队已经证明了该框架在提升图像编辑精度和增强场景美观度方面的卓越表现,相较于传统的图像编辑方法,本框架展现出了明显的优势。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











