北京航空航天大学、01.AI、香港理工大学、AIWaves、阿尔伯塔大学、滑铁卢大学、曼彻斯特大学、中国科学院自动化研究所、北京大学和香港科技大学的研究人员推出一个基于多模态token的新型基础模型MIO,它是一个基于多模态标记(如文本、图像、视频和语音)构建的基础模型,能够以一种端到端、自回归的方式理解和生成这些模态。简单来说,MIO就像一个多才多艺的艺术家,它可以读取和理解各种形式的创意素材,然后基于这些素材创作出新的艺术作品。例如,你有一张图片,上面是一只猫坐在沙发上。现在,你想知道如果猫跳起来会发生什么。MIO可以读取这张图片,理解场景中的物理规则,然后生成一系列连贯的帧,形成一个视频,展示猫跳起来的过程。
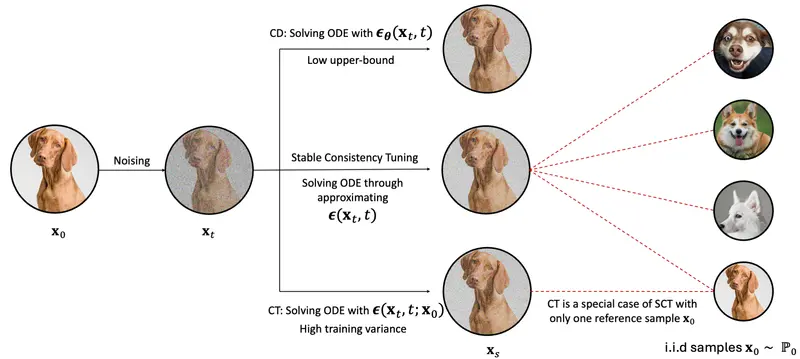
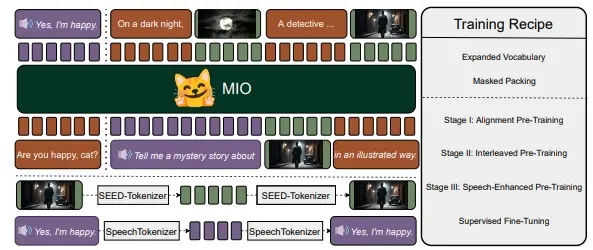
MIO使用因果多模态建模对四种模态的离散token混合进行训练。MIO经历了四个阶段的训练过程:(1)对齐预训练,(2)交错预训练,(3)语音增强预训练,(4)在多样化的文本、视觉和语音任务上进行全面监督的微调。我们的实验结果表明,与以前的双模态基线、任何到任何模型基线甚至模态特定基线相比,MIO表现出具有竞争力,甚至在某些情况下更优的性能。此外,MIO展示了其任何到任何特征的先进能力,例如交错视频文本生成、视觉思维链推理、视觉指导生成、指导性图像编辑等。
主要功能
- 多模态理解:MIO能够理解文本、图像、视频和语音。
- 多模态生成:它可以根据理解的内容生成新的文本、图像、视频和语音。
- 端到端生成:从输入到输出,整个过程是连续的,不需要额外的步骤。
主要特点
- 任何到任何的理解与生成:MIO不仅限于特定类型的输入或输出,它可以处理各种模态的混合。
- 多模态交错序列生成:MIO能够生成交错的多模态序列,比如视频和文本的混合。
- 开源:MIO的代码和模型将会公开,这意味着任何人都可以使用和改进它。
工作原理
- 多模态标记化:MIO使用特殊的标记化工具将图像、视频帧和语音转换成模型可以理解的标记。
- 因果多模态建模:MIO将这些标记当作输入,通过一个大型的语言模型进行训练,以预测下一个最合适的标记。
- 多模态去标记化:生成的标记随后被转换成相应的图像、视频或语音。
具体应用场景
- 内容创作:艺术家和设计师可以使用MIO来生成新的创意素材。
- 教育和培训:MIO可以用于创建教育内容,比如将静态图像转换成动态视频来解释复杂的概念。
- 娱乐和游戏:在游戏设计中,MIO可以用来生成游戏角色的动画和对话。
- 辅助设计:MIO可以帮助设计师通过文本描述来生成图像原型或动画草图。
总的来说,MIO是一个多功能的模型,它将多种类型的数据融合在一起,为创作和理解提供了新的可能性。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...