
中国科学院计算技术研究所和中国科学院大学的研究人员推出统一多模态框架UniPose,它用于理解、生成和编辑人体姿态。UniPose利用大语言模型(LLMs)来处理包括图像、文本和3D SMPL姿态在内的各种模态,实现对人体姿态的深入理解和控制。这个框架能够将3D姿态转换为离散的姿态标记,使得语言模型能够在同一词汇表中无缝处理姿态和文本,从而实现多模态任务的统一处理。
例如,你是一名动画师,需要根据文本描述创建一个特定的人体姿态。使用UniPose,你只需输入文本描述,例如“这个人用右腿支撑身体,左腿向后伸展,双手向两侧伸展”,UniPose就能生成符合描述的人体姿态。反过来,如果你有一张人物图片,UniPose也能理解图片中的姿态,并生成相应的文本描述。
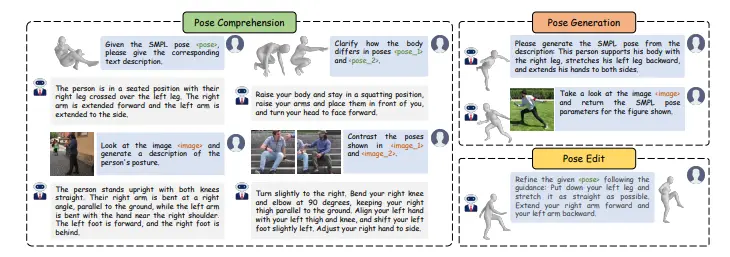
主要功能和特点
- 姿态理解(Pose Comprehension):从3D姿态或图像中生成自然语言描述。
- 姿态生成(Pose Generation):根据文本描述或图像生成3D姿态。
- 姿态编辑(Pose Editing):基于初始姿态和修改指令生成修正后的姿态。
主要特点包括:
- 统一表示空间:通过姿态标记器将3D姿态和文本统一表示,便于模型处理。
- 混合视觉编码器:结合CLIP视觉编码器和特定于姿态的视觉变换器,增强细粒度姿态感知能力。
- 混合注意力机制:对文本采用因果注意力,对姿态标记采用双向注意力,提高姿态生成和编辑的效果。
- 零样本泛化能力:无需额外训练即可适应未见任务。
工作原理
UniPose的工作原理包括以下几个关键步骤:
- 姿态标记器(Pose Tokenizer):将连续的3D姿态参数转换为离散的姿态标记序列。
- 视觉处理器(Visual Processor):使用CLIP和姿态特定的视觉编码器提取图像中的姿态相关信息。
- 姿态感知的语言模型(Pose-aware LLM):结合姿态标记和视觉特征,处理多种姿态相关任务。
- 混合注意力机制:对文本序列采用因果注意力,对姿态标记序列采用双向注意力,以处理非序列化的姿态信息。
具体应用场景
- 虚拟现实(VR)和增强现实(AR):在虚拟环境中创建和控制人物姿态。
- 动画和游戏制作:根据剧本或游戏情节生成角色姿态。
- 健康和运动分析:分析人体姿态,提供运动指导和健康建议。
- 安全监控:在监控视频中检测异常姿态,用于安全预警。
- 人机交互:通过理解人体姿态来改善人机交互体验
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











