
中国科学技术大学的研究人员推出人像视频编辑方法PortraitGen,该方法可以根据多模态提示对人像视频进行一致且富有表现力的编辑。例如,给定一段人物跳舞的视频,PortraitGen 可以根据文字提示 "将人物变成乐高风格" 或 "将人物变成像素游戏角色" 对视频进行编辑,同时保持人物动作和表情的自然连贯。
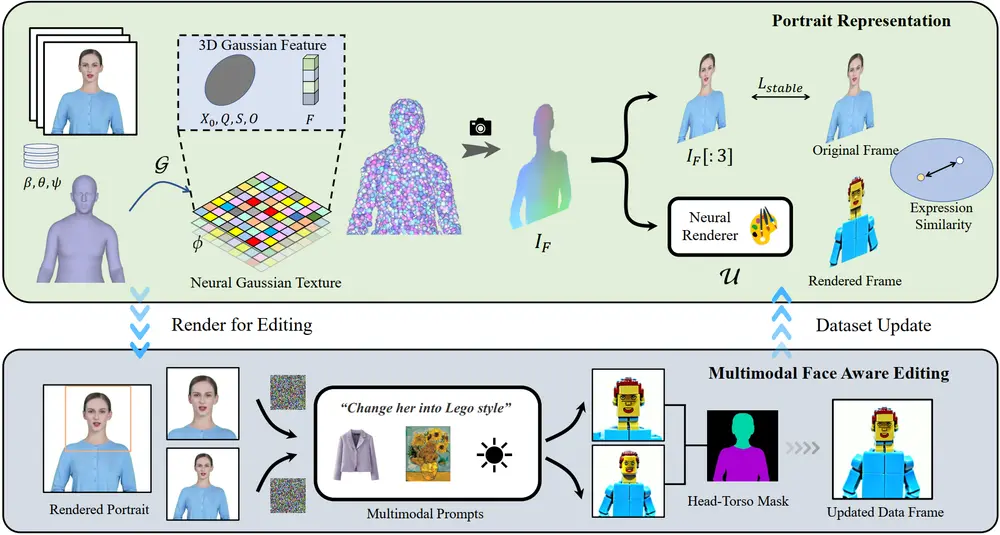
该方法将肖像视频帧提升到统一的动态 3D 高斯场,以确保帧之间的结构和时间一致性。此外,该方法还设计了一种新型神经高斯纹理机制,不仅能够实现复杂的风格编辑,还能实现超过 100FPS 的渲染速度。该方法通过从大型 2D 生成模型中提取的知识来整合多模态输入,并结合表情相似性引导和面向人脸的肖像编辑模块,有效地缓解了迭代数据集更新所带来的退化问题。广泛的实验表明,该方法在时间一致性、编辑效率和渲染质量方面均优于现有方法。该方法的广泛适用性在包括文本驱动的编辑、图像驱动的编辑和重新照明等各种应用中得到证明,突出了其在视频编辑领域具有巨大潜力。

主要功能:
- 文本驱动编辑:通过文本提示,比如“将她变成像素风格”,“PortraitGen”能够理解并按照这个风格对视频进行编辑。
- 图像驱动编辑:你可以提供一张参考图片,系统会将视频中的人物风格调整得和参考图类似。
- 重光照:改变视频的光照效果,比如从白天变为夜晚,或者增加特定的光影效果。
主要特点:
- 多模态提示:能够理解和处理多种输入提示,如文本、图像等。
- 3D和时间一致性:确保视频中的人物在编辑后,不仅在单个画面上看起来自然,而且在视频连续播放时也能保持一致性。
- 高速渲染:编辑过程快速,能够实现超过100FPS的渲染速度。
工作原理:
- 3D高斯场:将视频中的每一帧图像转换成一个3D动态高斯场,这有助于保持人物结构和时间上的连贯性。
- 神经高斯纹理机制:这是一种新颖的方法,它不仅能够进行复杂的风格编辑,还能实现快速渲染。
- 多模态输入融合:通过从大规模2D生成模型中提取知识,将多种输入方式融合到视频编辑中。
- 表情相似性引导和人脸感知编辑模块:在迭代数据集更新过程中,保持表情的自然和人脸结构的准确性。
具体应用场景:
- 电影和艺术制作:在电影后期制作中,可以用于改变角色的外观,或者创造不同的光照效果。
- 增强现实/虚拟现实(AR/VR):在虚拟环境中,可以根据用户的需要实时改变虚拟角色的外观。
- 社交媒体:用户可以轻松地编辑自己的视频,添加各种风格和特效,然后分享到社交平台。
- 游戏和娱乐:在游戏中,玩家可以自定义角色的外观,或者改变游戏内的视频内容。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











