韩国研究人员推出视觉语言模型CoLLaVO(Crayon Large Language and Vision mOdel),此模型旨在通过增强对象级别的图像理解能力,提高视觉语言模型(VLMs)在零样本(zero-shot)视觉语言任务中的性能。
CoLLaVO通过创新的视觉提示和学习策略,显著提升了视觉语言模型在理解和处理图像内容方面的能力,为视觉语言任务提供了一个强大的工具。

主要功能:
CoLLaVO的核心功能是通过引入一种名为“Crayon Prompt”的视觉提示调优方案,结合双重量化低秩适应(Dual QLoRA)学习策略,来提升模型对图像中对象的理解。这种增强的对象级别理解有助于模型在处理视觉语言任务时,如图像问答(VQA)、图像描述等,能够更准确地识别和理解图像内容。
主要特点:
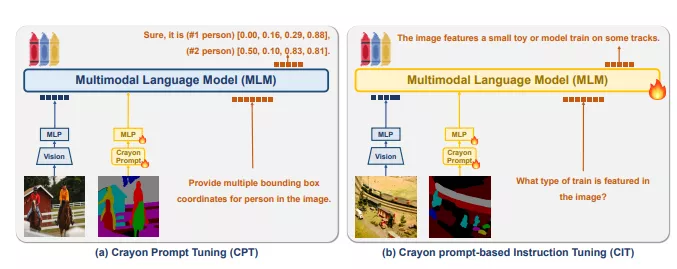
- Crayon Prompt:这是一种基于全景颜色地图的视觉提示,它包含了图像中对象的语义信息和编号。通过这种方式,CoLLaVO能够在保持图像原始视觉内容的同时,为模型提供关于图像中对象的详细信息。
- Dual QLoRA:这是一种学习策略,允许模型在保持对象级别图像理解的同时,通过视觉指令调优数据集来提高复杂视觉语言任务的性能,从而避免在调优过程中忘记之前学到的知识。
- 零样本性能:CoLLaVO在多个视觉语言基准测试中展示了显著的零样本性能提升,这意味着模型能够在没有额外训练的情况下,处理和理解新的、未见过的视觉语言任务。
工作原理:CoLLaVO的工作原理涉及以下几个关键步骤:
- 视觉编码器:使用CLIP模型作为视觉编码器,提取图像的特征。
- Crayon Prompt:利用全景分割模型生成的全景颜色地图,创建包含对象语义和编号信息的Crayon Prompt。
- 多模态语言模型(MLM):将Crayon Prompt与图像特征结合,通过MLM进行处理,以增强对象级别的图像理解。
- 双重量化低秩适应(Dual QLoRA):在训练过程中,交替使用Crayon Prompt和视觉指令调优数据集,以保持对象级别图像理解能力,同时提高复杂视觉语言任务的性能。
具体应用场景:CoLLaVO的应用场景包括但不限于:
- 图像问答(VQA):在没有额外训练的情况下,CoLLaVO能够理解和回答关于图像内容的问题。
- 图像描述:CoLLaVO能够生成描述图像内容的文本,包括图像中的对象、场景和活动。
- 视觉语言任务:CoLLaVO可以处理各种视觉语言任务,如图像分类、对象检测、图像生成等,同时保持对图像内容的深入理解。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











