FiT(Flexible Vision Transformer)是一款新型图像生成模型,基于Transformer架构,旨在生成具有无限制分辨率和长宽比的图像。
传统的图像生成模型往往受限于其训练时的分辨率,而FiT则通过其独特的设计,与 Sora一样,可以在训练和推理阶段轻松适应不同的长宽比,从而提高了分辨率的泛化能力并消除了由图像裁剪引起的偏差。

这样做的好处是,FiT能够灵活地适应不同的图像尺寸,生成高分辨率和任意宽高比的图像,而不受预定义尺寸的限制。
主要功能:
FiT的主要功能是生成具有无限制分辨率和长宽比的图像。这意味着,无论输入的图像大小如何,FiT都能够生成高质量的图像输出。此外,FiT还能够消除由图像裁剪引起的偏差,进一步提高了生成图像的质量。
- 生成任意分辨率和宽高比的图像。
- 在训练和推理阶段保持图像的原始宽高比,避免图像被裁剪或失真。
- 提高了图像生成的灵活性和分辨率的泛化能力。
主要特点:
- 灵活的训练流程:FiT在训练过程中保持图像的原始宽高比,通过将高分辨率图像调整到预设的最大令牌(token)长度,确保图像不被裁剪。
- 独特的网络架构:FiT采用了2D旋转位置嵌入(RoPE)和Swish-Gated线性单元(SwiGLU),这些改进有助于处理不同大小的图像。
- 训练无关的分辨率外推方法:FiT能够通过特定的技术在不进行额外训练的情况下,生成超出训练分辨率的图像。
工作原理:
FiT基于Transformer架构。它首先将输入的图像分割成一系列动态大小的token(令牌)。然后,这些token被送入一个精心设计的网络中进行处理。在处理过程中,FiT采用了多种技术来增强其灵活性,包括训练时的自由外推技术和精心调整的网络结构。最后,经过处理的token被重新组合成输出图像。
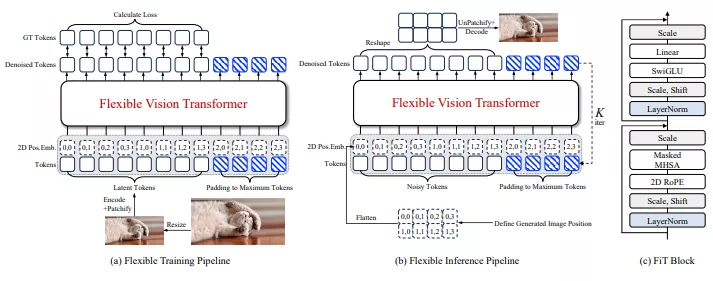
- 预处理:在预处理阶段,FiT避免裁剪或调整低分辨率图像,而是将高分辨率图像调整到最大分辨率限制。
- 训练:图像首先被编码为潜在代码,然后转换为令牌序列。这些序列被填充到最大令牌长度,以便批量处理。在训练过程中,只计算去噪输出令牌的损失。
- 推理:在推理阶段,定义生成图像的位置图,从高斯分布中采样噪声令牌,经过多次去噪迭代后,根据预定义的位置图重塑和解包令牌,得到最终生成的图像。
应用场景:
FiT的应用场景非常广泛。它可以用于生成各种尺寸和长宽比的图像,满足不同领域的需求。例如,在图像处理领域,FiT可以用于生成高分辨率的图像,提高图像的质量和清晰度。在计算机视觉领域,FiT可以用于生成不同长宽比的图像,以适应不同的应用场景。此外,FiT还可以用于生成具有特定分辨率和长宽比的图像,以满足特定领域的需求,如医学图像处理、卫星图像处理等。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











