
威斯康星大学麦迪逊分校、哥伦比亚大学和微软的研究人员推出的GLIGEN模型,用于将Stable Diffusion模型扩展为可定制的模型。这个模型的核心目标是让计算机能够根据文本描述生成图像,并且能够更精确地控制图像中的内容和布局。简单来说,就是让计算机不仅理解你描述的是什么,还能知道这些东西在图像中应该放在哪里。
实验结果显示,GLIGEN在COCO和LVIS数据集上表现优于现有的监督布局到图像生成方法,且在开放世界中具有很好的泛化能力。

主要功能:
GLIGEN模型能够根据文本描述(比如“一个坐在餐厅里的女人面前有一块披萨”)生成相应的图像。它不仅能够理解文本内容,还能处理额外的“grounding”(定位)信息,比如物体的边界框、关键点、深度图等,来更精确地生成图像。
主要特点:
- 开放世界定位能力:GLIGEN能够在没有见过的物体或概念上进行定位,这意味着它能够生成训练数据集中没有出现过的新物体。
- 零样本性能:在没有额外训练的情况下,GLIGEN在COCO和LVIS数据集上的表现超过了现有的监督布局到图像的基线模型。
- 灵活性:模型支持多种定位输入,如文本实体+边界框、图像实体+边界框、图像风格+文本+边界框、关键点、深度图、边缘图、法线图和语义图等。
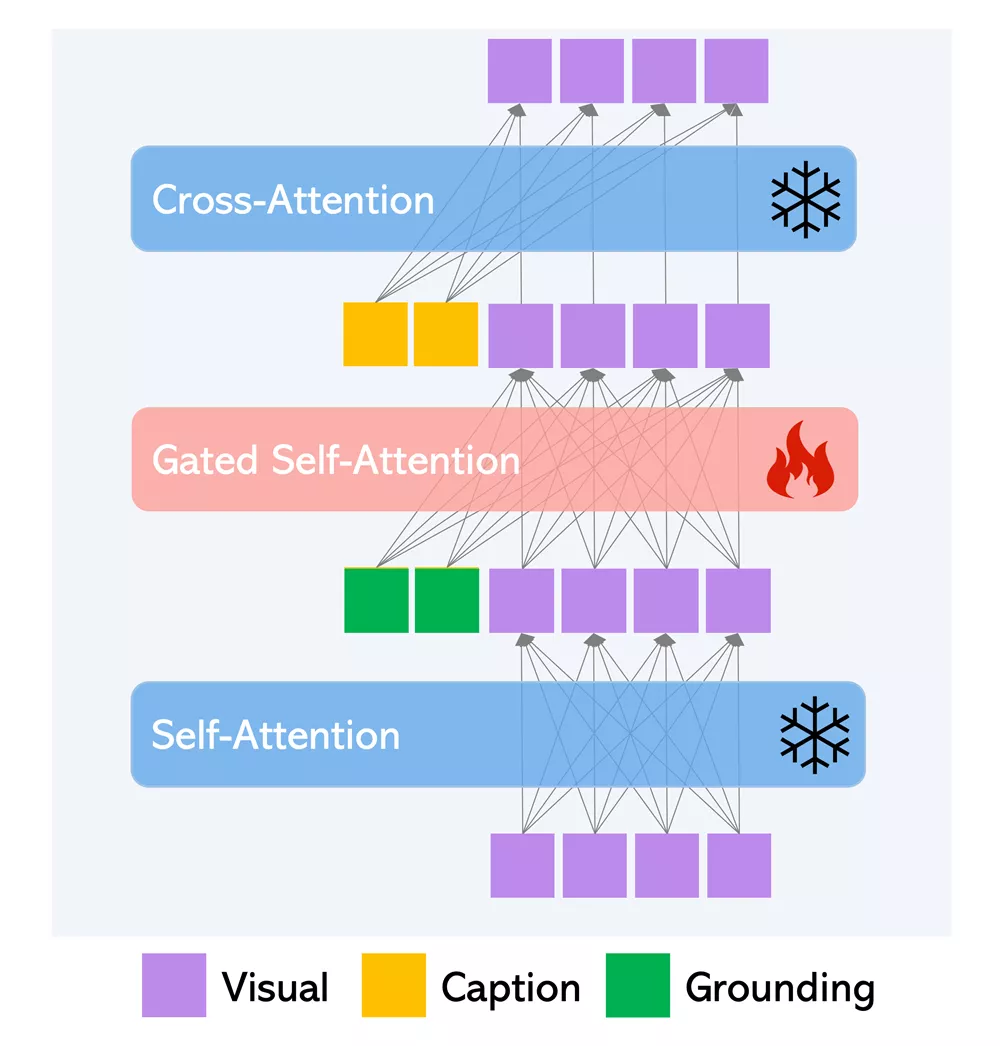
工作原理:
GLIGEN的工作原理基于一个预训练的文本到图像扩散模型,这个模型已经学会了如何根据文本描述生成图像。为了增加定位能力,研究者们在模型中添加了新的可训练层,并通过一个门控机制(gated mechanism)将定位信息注入到这些新层中。在训练过程中,这些新层逐渐与预训练模型融合,使得模型能够在生成过程中灵活地利用这些定位信息。在推理(生成图像)阶段,模型可以通过调整门控参数来平衡图像质量和定位准确性。
- 预训练模型:基于大规模预训练的文本到图像生成模型。
- 权重冻结:在训练中冻结原始模型的所有权重。
- 注入接地信息:通过门控自注意力机制,将接地条件信息注入模型。
- 渐进学习:模型逐步学习利用接地信息进行生成,同时保留预训练知识。

GLIGEN是一个强大的工具,它结合了自然语言处理和计算机视觉,使得图像生成更加灵活和精确,为各种创意和应用提供了可能。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











