
随着多媒体内容的增长,学习一个鲁棒的视频变分自编码器(VAE)对于减少视频冗余和促进高效视频生成变得越来越重要。直接将图像VAE应用于单个帧可能会导致时间不一致性和次优压缩率,因为缺乏对时间维度的有效处理。现有的视频VAE虽然开始解决时间压缩的问题,但在重建性能上仍有不足,尤其是在保持细节和时间一致性方面。
VideoVAE+的设计理念
香港科技大学的研究人员针对上述问题提出了一种新颖且强大的视频自编码器——VideoVAE+,旨在提高视频数据压缩和生成的效率,特别是在处理大运动场景的视频时,能够保持高保真度和时间一致性。例如,我们有一段视频,内容是一个人在跑步,这段视频包含了快速的运动和变化。传统的视频压缩方法可能会在这种大运动场景中丢失细节或产生模糊,而这VideoVAE+能够更好地处理这种情况,通过有效的空间和时间压缩,保留视频中的细节和运动流畅性。

主要功能:
- 高保真视频编码:模型能够将视频编码到一个紧凑的潜在空间,并从中重建视频,保持高度的空间和时间保真度。
- 大运动处理:特别优化了对大运动场景的处理能力,减少了运动模糊和细节失真。
- 跨模态学习:利用文本信息来增强视频的重建质量,尤其是在细节保留和时间稳定性方面。
主要特点:
- 时间感知的空间压缩:通过扩展图像VAE到3D VAE,模型能够更好地编码和解码空间信息。
- 轻量级运动压缩模型:进一步压缩时间维度,提高压缩率。
- 跨模态视频VAE:首次提出利用文本描述信息来辅助视频自编码过程。
- 图像和视频联合训练:模型能够在图像和视频数据上进行训练,提高了重建质量和模型的通用性。
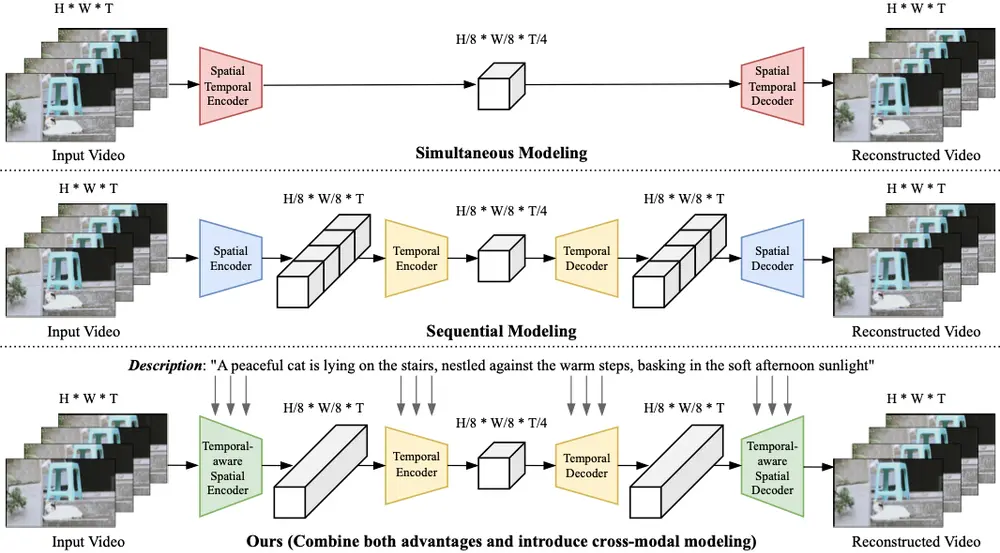
其设计考虑了以下关键点:
时间感知的时空压缩:
- 传统方法通过扩展图像VAE为3D VAE来纠缠空间和时间压缩,但这种方法可能会引入运动模糊和细节失真伪影。
- VideoVAE+提出了时间感知的时空压缩机制,以更精细地编码和解码空间信息,从而避免上述问题,并提高时间和空间的一致性。
轻量级运动压缩模型:
- 为了进一步进行时间压缩并提升效率,VideoVAE+集成了一个轻量级的运动压缩模型。该模型专注于捕捉帧间的变化,从而在不显著增加计算复杂度的情况下,增强时间维度上的压缩效果。
文本引导的多模态融合:
- 利用文本到视频数据集中固有的文本信息,VideoVAE+将文本引导融入模型中。这不仅有助于指导视频编码过程,还提升了重建质量,特别是在细节保留和时间稳定性方面。
- 文本引导能够帮助模型更好地理解视频内容,确保生成的视频在语义上更加连贯和准确。
联合训练策略:
- 通过在图像和视频上进行联合训练,VideoVAE+提高了模型的通用性。这种策略不仅增强了重建质量,还使模型具备了处理图像和视频的能力,扩大了其应用范围。
实验结果与优势
- 卓越的重建质量:与近期强大的基线方法相比,VideoVAE+在多个评估指标上表现出色,尤其在细节保留和时间一致性方面。
- 高效的压缩性能:通过时间感知的时空压缩和轻量级运动压缩模型,VideoVAE+实现了高效的视频压缩,减少了冗余而不牺牲质量。
- 多模态能力:文本引导的加入使得VideoVAE+能够在视频生成过程中利用额外的语义信息,从而产生更加丰富和连贯的内容。
- 广泛的适用性:联合训练策略使得VideoVAE+不仅能用于视频编码,还能处理图像编码任务,展示了其广泛的适用性和灵活性。

© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











