
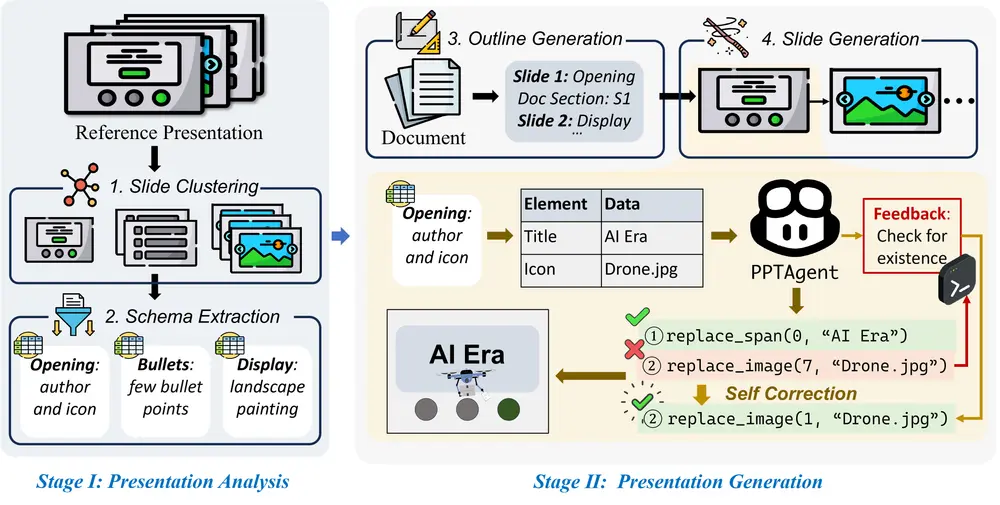
自回归(AR)模型在文本和图像生成方面取得了显著的进展,但其逐令牌生成的过程导致了速度上的局限性。为了克服这一问题,清华大学和微软研究院的研究人员提出了一项雄心勃勃的任务:能否将预训练的AR模型调整为只需一步或两步即可生成输出? 如果成功,这将极大地提升AR模型的应用效率和部署灵活性。
现有的尝试通过一次性生成多个令牌来加速AR生成的工作,由于未能捕捉到令牌之间的条件依赖性,导致无法准确反映输出分布,从而限制了少步生成的有效性。为了解决这个问题,研究人员提出了蒸馏解码(Distilled Decoding, DD)技术,该技术利用流匹配创建从高斯分布到预训练AR模型输出分布的确定性映射,并训练一个网络来蒸馏这一映射,以实现高效的少步生成。它用于加速自回归(Autoregressive,AR)模型在图像和文本生成任务中的采样步骤。DD的目标是将预训练的AR模型适应为只需一步或几步就能生成输出的能力,从而显著提高AR模型的开发和部署效率。
- 项目主页:https://imagination-research.github.io/distilled-decoding
- GitHub:https://github.com/imagination-research/distilled-decoding
例如,我们有一个预训练的AR模型,用于从文本描述生成图像。传统的AR模型可能需要256个步骤(或“token-by-token”)来生成一张图像,而DD方法可以将这个过程减少到只需1步或2步,大大加快了生成速度。例如,对于一个名为LlamaGen的模型,DD能够在保持图像质量可接受的情况下,将生成步骤从256步减少到1步,实现了217.8倍的速度提升。

主要功能:
- 加速生成:DD能够显著减少AR模型生成数据(如图像或文本)所需的步骤。
- 保持输出质量:在加速的同时,DD尽量保持生成数据的质量,避免过度牺牲输出的多样性和准确性。
主要特点:
- 一步生成能力:DD能够实现从噪声到数据的直接映射,从而在单步中生成完整的输出。
- 无需原始训练数据:DD的训练过程不需要原始AR模型的训练数据,这使得DD更加实用,尤其是在训练数据不可用的情况下。
- 灵活性:DD允许在生成质量和生成步骤之间进行灵活的权衡,支持更多的生成步骤以改善数据质量。
蒸馏解码的核心思想
DD的核心在于它创新地结合了AR方法与流匹配,解决了少步生成中的关键挑战。具体来说,DD的工作流程包括以下几个步骤:
- 数据集生成:首先,DD构建了一个噪声-数据对的训练集。具体而言,它从标准高斯分布中随机采样噪声序列,并计算这些序列在预训练AR模型下的最终状态,即轨迹的终点。
- 训练:接下来,DD训练一个模型,给定特定中间点(包括起点)作为输入,预测轨迹的终点。这个过程使得新模型能够学习如何快速从噪声转换为符合目标分布的数据。
- 采样:最后,在实际应用中,DD可以从纯噪声序列开始进行采样。通过获取最终值后返回到更接近的中间点并重新预测,可以进一步提高生成质量。此外,还可以在这个过程中引入预训练的AR模型,以实现更精细的质量-时间权衡。
实验结果
DD在最先进的图像AR模型上进行了评估,展示了令人鼓舞的结果:
- 对于需要10步生成(680个令牌)的VAR模型,DD实现了单步生成,达到了6.3倍的加速效果。尽管ImageNet-256上的FID分数从4.19增加到了9.96,但增幅是可接受的。
- 对于LlamaGen,DD将生成过程从256步减少到1步,实现了217.8倍的加速,FID从4.11增加到11.35,仍然保持了较好的生成质量。
- 在文本到图像生成方面,DD同样表现出色,将LlamaGen的生成从256步减少到2步,FID仅从25.70增加到28.95。
相比之下,基线方法完全失败,FID分数超过100,表明DD在保持生成质量的同时显著提升了生成速度。
亮点与贡献
🌟 彻底分析现有方法的局限性:研究团队深入探讨了为何现有方法难以实现极少步生成的原因。 🌟 创新性的解决方案:DD首次将AR方法与流匹配结合,有效解决了少步生成的问题。 🌟 开创性的成果:这是首个展示使用SOTA图像AR方法(如VAR和LlamaGen)进行1步采样的可行性的工作,挑战了AR模型天生缓慢的普遍观念,并为高效的AR生成开辟了新的机会。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...











