清华大学、香港中文大学(深圳)、国际数字经济学院和香港科技大学的研究人员推出人工智能系统MotionLLM,它的主要任务是理解和解释人类行为,特别是通过分析人体动作和视频。例如,你有一台智能相机,它不仅能录制你的日常活动,还能理解你在做什么,甚至能够预测你下一步可能会做什么。这就是MotionLLM的魔法所在。
- 项目主页:https://lhchen.top/MotionLLM
- GitHub:https://github.com/IDEA-Research/MotionLLM
- Demo:https://demo.humotionx.com
之前多模态(即,视频和动作模态)人类行为理解领域,通过利用大语言模型的强大能力。与近期专为仅视频或仅动作理解设计的大语言模型不同,开发人员认为理解人类行为需要从视频和动作序列(例如,SMPL序列)中进行联合建模,以便有效地捕捉细腻的身体部位动态和语义。鉴于此,开发人员提出了MotionLLM,一个简单而有效的框架,用于人类动作理解、描述生成及推理。具体而言,MotionLLM采用了一种统一的视频-动作训练策略,该策略利用现有粗略的视频-文本数据和精细的动作-文本数据的互补优势,以提取丰富的时空洞察。此外,我们收集了一个庞大的数据集MoVid,包含多样的视频、动作、描述和指示信息。另外,开发人员提出了MoVid-Bench,带有精心的手动注释,以便更好地评估在视频和动作上的人类行为理解能力。
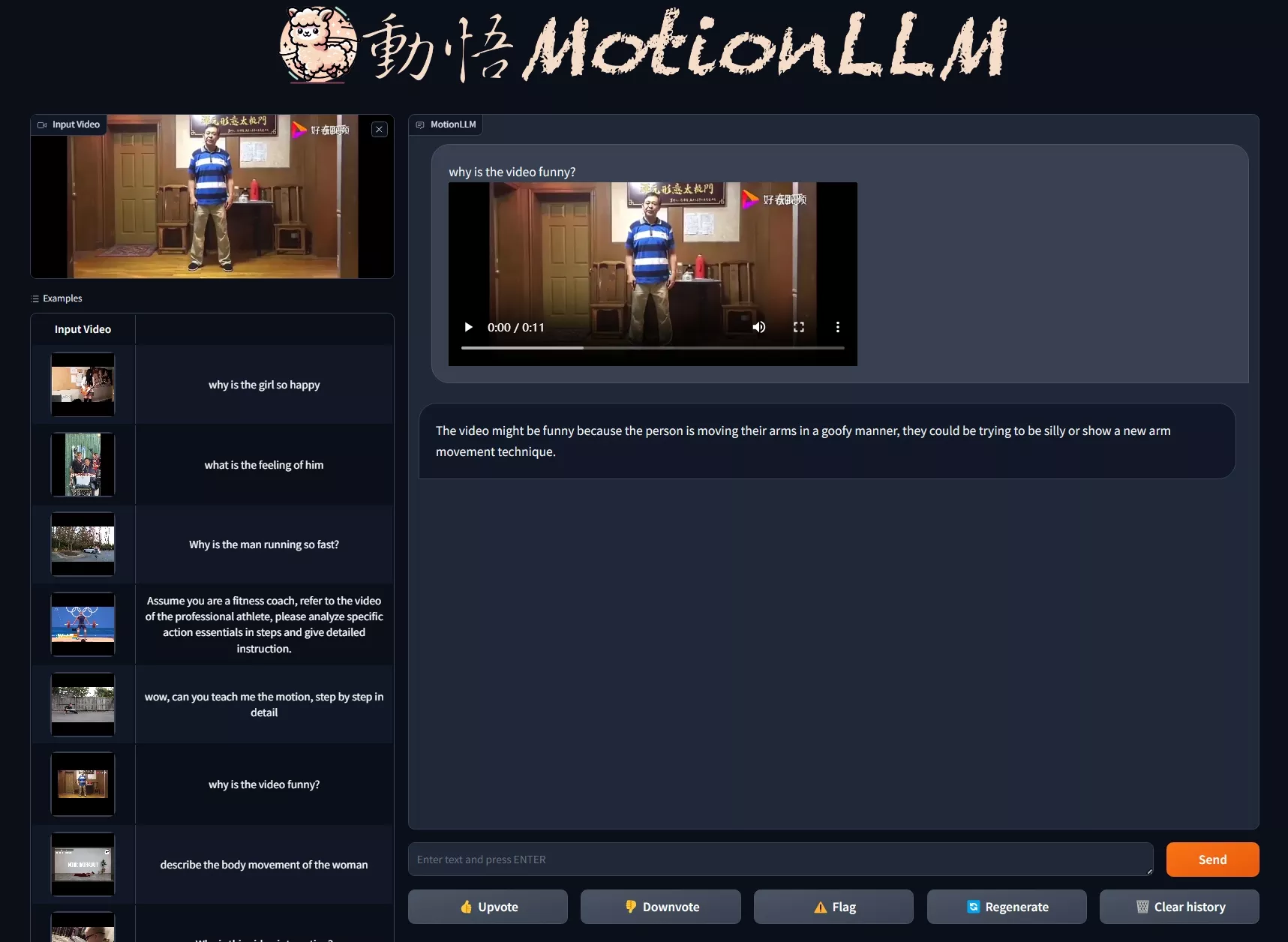
主要功能:
- 理解人体动作:MotionLLM能够分析人体动作序列,比如你在做瑜伽或者跳舞时的每一个姿势。
- 视频内容理解:它也能解析视频,理解视频中人物的行为和动作。
- 行为推理:系统不仅能够识别动作,还能够推理出动作背后的含义,比如判断某个动作是否是某种运动的一部分。
主要特点:
- 多模态学习:MotionLLM结合了视频和动作数据,以更全面地理解人类行为。
- 大规模数据集:研究者们收集并创建了一个包含多种视频、动作、标题和指令的大型数据集(MoVid),来训练和评估模型。
- 先进的评估基准:通过MoVid-Bench,一个为评估模型对人类行为理解能力而设计的基准测试,可以细致地评估模型的性能。
工作原理:
MotionLLM使用大型语言模型(LLMs)来处理和理解输入的视频和动作数据。它首先通过视觉编码器处理这些视觉提示,然后通过一个特殊的转换器(V-L translator)将视觉嵌入转换为文本序列。这个过程分为两个阶段:
- 模态转换:在第一阶段,模型学习如何将视觉数据(视频或动作)转换为语言模型能够理解的格式。
- 指令调整:在第二阶段,模型通过指令调整数据进一步微调,以提高对复杂指令的响应能力和理解力。

具体应用场景:
- 智能健身教练:MotionLLM可以根据你的动作给你提供健身指导,比如纠正你的瑜伽姿势或提供个性化的锻炼建议。
- 安全监控:在需要监控的场合,MotionLLM可以帮助识别异常行为,提高安全性。
- 辅助视障人士:对于视觉受限的人士,MotionLLM可以作为辅助工具,通过解释周围人的动作来帮助他们更好地理解环境。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...