
来自清华大学、无问芯穹(Infinigence AI)、卡内基梅隆大学和上海交通大学的研究人员推出新技术DiTFastAttn,它专门用于压缩和加速一种称为Diffusion Transformers(扩散变换器,简称DiT)的模型。DiT是一种在图像和视频生成方面表现出色的人工智能模型,但它在计算上存在一些挑战,尤其是当处理高分辨率内容时。
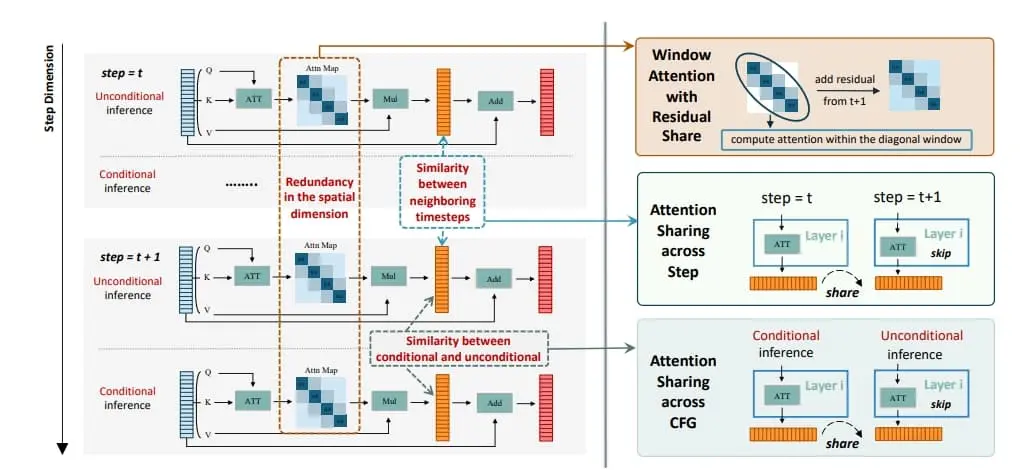
DiTFastAttn是一种创新的后训练压缩策略,旨在缓解DiT的计算瓶颈问题。通过分析,研究团队发现了DiT推理阶段注意力计算存在的三项核心重复计算问题:1. 空间维度上,众多注意力头集中处理局部信息的现象;2. 时间维度上的重复,即相邻时间步的注意力输出高度相似;3. 在条件与非条件推断间发现的功能重叠,表现为两者间存在显著相似性。
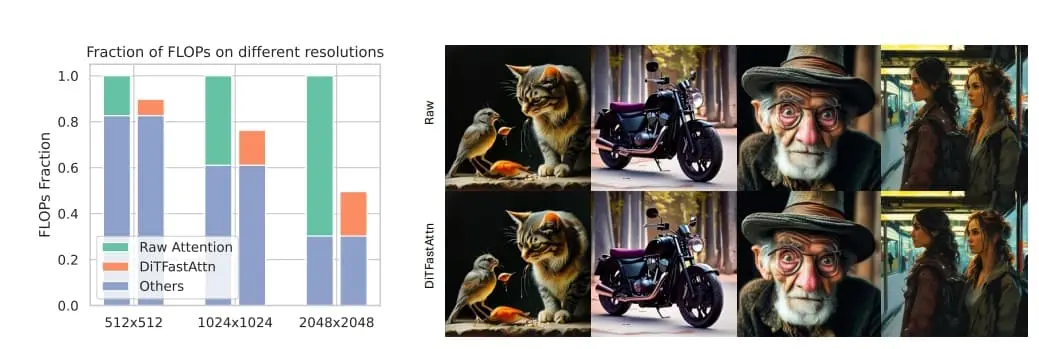
为有效应对上述冗余,研究团队设计了三项技术方案:1. 搭配残差缓存的窗口注意力机制,旨在削减空间维度的计算重复;2. 利用时间步间相似性的“时间相似性减缩”技巧;3. 以及在条件生成流程中实施“条件冗余剔除”,避免不必要的重复计算。为了验证DiTFastAttn的效果,研究团队将其应用于DiT、PixArt-Sigma的图像生成任务及OpenSora的视频生成任务中。实验结果彰显了该方法的强大效能:在高分辨率图像生成场景下,它能最高减少88%的浮点运算量(FLOPs),并实现高达1.6倍的加速效果。
例如,假设你想要生成一幅高分辨率的山水画,使用传统的DiT模型可能需要很长时间来计算每一处细节。但是,通过使用DiTFastAttn,模型可以更快地生成图像,因为它只关注必要的视觉信息,并且通过共享和重用计算结果来减少不必要的重复工作。这样,你就能得到一幅既快速生成又美观的山水画。
主要功能:
- DiTFastAttn的主要功能是减少DiT模型在推理(即生成图像和视频时)过程中的计算量,从而加快生成速度并降低硬件资源需求。
主要特点:
- 后训练压缩方法:这是一种在模型训练完成后应用的压缩技术,不需要重新训练模型。
- 针对自注意力机制的优化:通过识别和减少自注意力计算中的冗余,DiTFastAttn提高了模型的效率。
- 三种压缩技术:包括窗口注意力与残差共享(WA-RS)、跨时间步的注意力共享(AST)和跨分类器自由引导的注意力共享(ASC)。
工作原理:
- 窗口注意力与残差共享(WA-RS):通过在局部窗口内计算注意力,减少对空间冗余的关注,同时通过残差共享技术保留长距离依赖关系。
- 跨时间步的注意力共享(AST):利用连续步骤间注意力输出的相似性,通过共享早期步骤的注意力输出来减少计算。
- 跨分类器自由引导的注意力共享(ASC):在有条件和无条件推理之间共享注意力输出,以减少在条件生成中的冗余计算。
具体应用场景:
- 图像生成:使用DiTFastAttn,可以在保持图像质量的同时,显著减少生成高分辨率图像所需的计算量。
- 视频生成:在视频生成任务中,DiTFastAttn可以减少每一帧的计算需求,从而加快整个视频的生成速度。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











