
巴伊兰大学、英伟达和特拉维夫大学的研究人员推出新型文生图模型CountGen,它能够根据文本提示准确地生成指定数量的对象。在以往的技术中,尽管文本到图像的扩散模型取得了巨大成功,但它们在控制生成图像中对象数量方面却面临挑战。例如,一个食谱要求在图像中展示六个鸡蛋,模型可能只生成了两个鸡蛋,使用CountGen模型可以根据这一文本提示生成一张包含正好六个鸡蛋的图片,避免了生成五个或七个鸡蛋的错误情况。这在自动生成教学材料、食谱书或任何需要精确视觉表示的场合都非常有用。

主要功能:
- CountGen能够理解文本中提到的对象数量,并在生成的图像中准确地反映这一数量。
- 它能够检测生成过程中的对象数量是否与文本描述相符,并进行相应的调整。
主要特点:
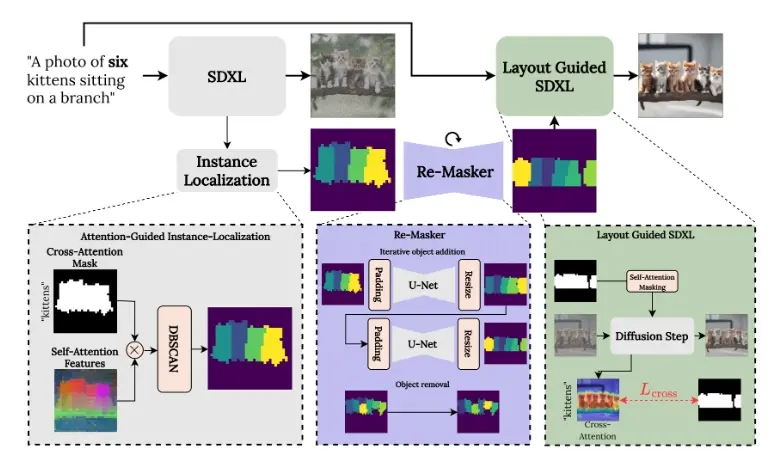
- 对象身份特征识别:CountGen通过分析扩散模型中的自注意力层,识别出能够携带对象身份信息的特征。
- 布局修正网络(ReLayout):如果检测到生成的对象数量与文本描述不符,CountGen会使用ReLayout网络来预测缺失对象的形状和位置,并指导去噪过程生成正确数量的对象。
- 无需外部布局信息:与以往需要手动设计或使用大型视觉-语言模型提出布局的方法不同,CountGen直接使用扩散模型本身的先验来创建布局。
工作原理:
- 对象实例检测:在去噪过程的早期阶段,CountGen利用自注意力层的特征来检测和计数对象实例。
- 布局修正:如果检测到生成的对象数量不正确,ReLayout网络会生成一个新的布局,添加或移除对象实例,同时保持场景结构的一致性。
- 基于布局的图像生成:在修正布局后,CountGen使用一种推理时优化方法,确保生成的图像遵循输入布局,从而生成数量准确的对象。
具体应用场景:
- 技术文档:在需要准确展示多个组件或元素的技术图纸或文档中。
- 儿童书籍:在讲述故事时,确保故事中提到的每个角色或物品都能在插图中准确呈现。
- 食谱说明:在食谱中,确保步骤图准确地展示了所需的食材数量。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











