
上海人工智能实验室推出CosmicMan,这是一款专注于生成高保真人类图像的文本到图像基础模型。CosmicMan能够生成外观精细、结构合理,并且与详细描述精确对齐的逼真人类图像。
CosmicMan成功的核心在于其对数据和模型的新见解和独特视角:
(1)数据质量和可扩展的数据生产流程对于训练模型得出高质量结果至关重要。因此,团队提出了一种新的数据生产范式——Annotate Anyone,它作为一个持续的数据飞轮,随着时间的推移,能够以准确且成本效益高的方式生成高质量数据。基于这一范式,开发团队构建了一个名为CosmicMan-HQ 1.0的大规模数据集,其中包含600万张平均分辨率为1488x1255的高质量真实世界人类图像,每张图像都附有来自1.15亿个不同粒度属性的精确文本注释。
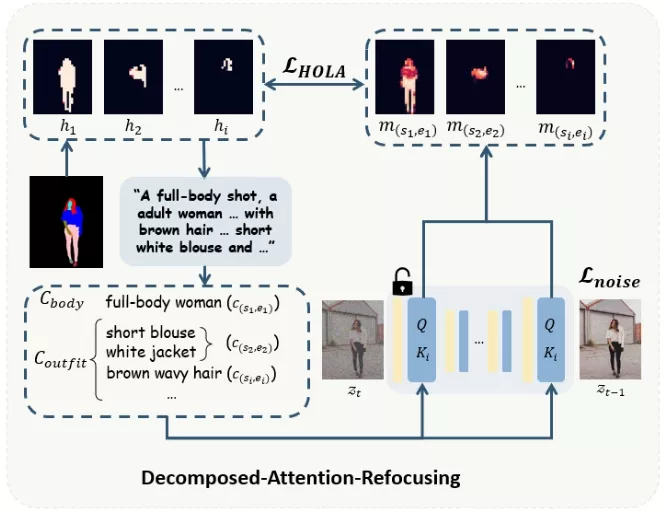
(2)专门为人类设计的文本到图像基础模型必须既实用又高效——既要易于集成到下游任务中,又要能够生成高质量的人类图像。因此,开发团队提出以分解的方式建模密集文本描述与图像像素之间的关系,并推出了分解注意重新聚焦(Daring)训练框架。它能够无缝分解现有文本到图像扩散模型中的交叉注意特征,并在不添加额外模块的情况下实现注意重新聚焦。通过Daring,开发团队发现将连续文本空间明确离散化为与人类身体结构对齐的几个基本组,是轻松解决不匹配问题的关键所在。

主要功能和特点:
- 高保真图像生成: CosmicMan能够生成非常细致和真实的人类图像,包括人物的外观、服装、发型等细节。
- 文本与图像对齐: 它能够确保生成的图像与文本描述紧密对应,减少描述与图像不一致的问题。
- 大规模数据集: 该模型使用了CosmicMan-HQ 1.0数据集,这是一个包含600万高质量真实世界人类图像的数据集,每个图像都有精确的文本注释。
- 易于集成: CosmicMan设计为易于集成到下游任务中,这意味着它可以轻松地与其他系统或应用程序结合使用。
工作原理:
CosmicMan的核心是一个名为“Decomposed-AttentionRefocusing (Daring)”的训练框架。这个框架通过分解文本描述和图像像素之间的关系来工作。它首先将文本描述分解成与人体结构相对应的固定组,然后通过一种称为HOLA(Human Body and Outfit Guided Loss for Alignment)的新损失函数来指导网络学习如何在组级别上重新聚焦注意力。这样,模型就能够更准确地将文本描述中的每个细节映射到图像的相应部分。
具体应用场景:
- 虚拟试衣: 电子商务网站可以使用CosmicMan来生成模特穿着不同服装的图像,帮助顾客在购买前更好地了解产品。
- 个性化内容创作: 艺术家和设计师可以利用这个模型根据他们的创意描述来生成独特的人物插画或角色设计。
- 游戏和娱乐: 游戏开发者可以集成CosmicMan来创建逼真的游戏角色或者为虚拟世界生成多样化的NPC(非玩家角色)。
- 时尚和零售: 时尚品牌可以使用这个技术来展示他们的服装在不同体型和肤色的人身上的效果。
CosmicMan是一个强大的工具,它通过结合先进的AI技术和大规模的高质量数据集,为人类图像生成领域带来了新的可能性。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











