
来自香港中文大学、商汤科技和上海人工智能实验室的研究人员推出新型文生图模型CoMat,这是一种具有图像到文本概念匹配机制的端到端扩散模型微调策略。开发团队借助图像字幕模型来评估图像与文本的对齐程度,并引导扩散模型重新关注那些被忽略的令牌(tokens)。此外,开发团队还提出了一种新颖的属性集中模块,用以解决属性绑定问题。
无需任何图像或人类偏好数据,开发团队仅使用了2万个文本提示对SDXL进行微调,从而得到了CoMat-SDXL。大量实验表明,CoMat-SDXL在两个文本到图像对齐基准测试中均显著优于基准模型SDXL,并达到了业内领先水平。

例如,你给这个模型一段描述,比如“一只穿着学士服、戴着毕业帽的猫头鹰”,然后模型就能根据这个描述生成一张图片。但是,CoMat不仅仅是生成任何图片,它的特别之处在于能够更好地理解文本中的每个细节,并确保这些细节在生成的图片中得到准确体现。
主要功能和特点:
- 文本与图像的精确对齐: CoMat通过一个图像到文本的概念匹配机制,确保生成的图片与文本描述紧密结合,每个细节都能在图片中找到对应。
- 改进的属性绑定: 它还引入了一个属性集中模块,专门解决属性(如颜色、形状)与实体(如猫头鹰、学士服)的精确绑定问题。
- 无需额外数据: CoMat的训练只需要文本提示,不需要图像或人类偏好数据,这使得模型的训练更加高效和便捷。
工作原理:
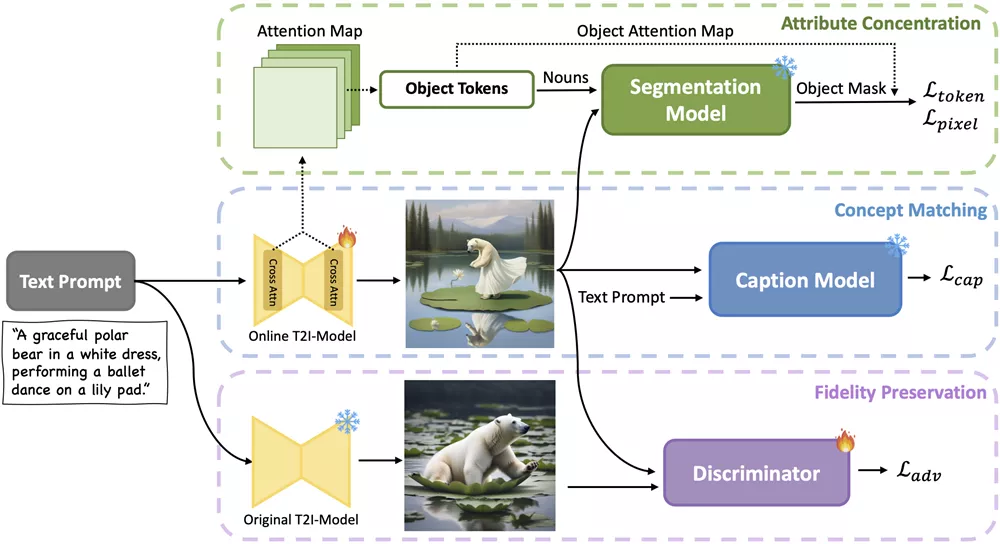
- 概念匹配: 首先,CoMat根据文本提示生成一张图片,然后使用图像描述模型来评估图片与文本的对齐程度。如果发现某些概念在图片中缺失,模型会被引导回去关注那些被忽略的文本部分。
- 属性集中: 接着,CoMat通过分析文本中的实体和属性,并使用图像分割技术来确定实体在图片中的位置,然后确保这些属性只在实体的区域内被激活。
- 保真度保留: 为了确保生成的图片质量不下降,CoMat还引入了一个对抗性损失,通过一个鉴别器来区分原始模型和经过微调的模型生成的图片,以避免过度拟合。
具体应用场景:
- 创意设计: 艺术家和设计师可以使用CoMat来生成初步的设计草图,节省时间和资源。
- 社交媒体内容创作: 社交媒体内容创作者可以利用CoMat根据用户的描述生成独特的图像,增加内容的吸引力。
- 教育和培训: 教育工作者可以利用CoMat来创造教学材料,帮助学生更好地理解复杂的概念。
CoMat是一个强大的工具,它通过更好地理解和执行文本描述,提高了文本到图像生成的质量和准确性。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











