
在个性化生成任务中,扩散模型(Diffusion Models)已经取得了显著的成就。传统的无需调优的方法通常通过平均多个参考图像的图像嵌入作为注入条件来编码,但这种与图像无关的操作无法在图像之间进行交互以捕捉多个参考图像中的一致视觉元素。尽管基于调优的低秩适应(LoRA)可以通过训练过程有效提取多个图像中的一致元素,但它需要对每个不同的图像组进行特定的微调,这在实际应用中成本高昂且效率低下。
香港中文大学、商汤科技研究院和上海AI实验室的研究人员提出了EasyRef,这是一种新颖的即插即用适应方法,使扩散模型能够以多个参考图像和文本提示为条件。这种方法的核心在于利用多模态大语言模型(MLLM)的多图像理解和指令跟随能力,通过提示它捕捉基于指令的一致视觉元素。
- 项目主页:https://easyref-gen.github.io
- GitHub:https://github.com/TempleX98/EasyRef
- 模型:https://huggingface.co/zongzhuofan/EasyRef
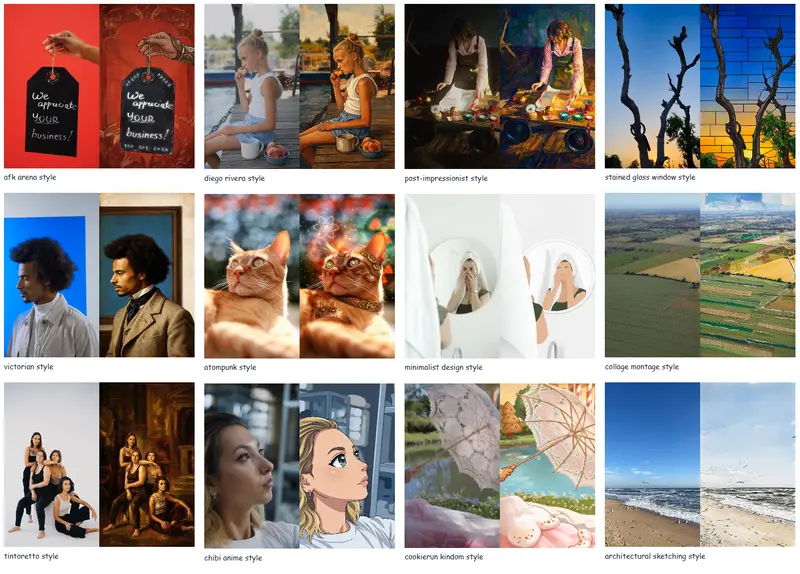
例如,一个用户想要生成一张“梵高风格的女孩在学校音乐室弹电吉他”的图像。用户可以提供几张梵高风格的参考图像、学校音乐室的图片以及电吉他的图片,以及文本提示“梵高风格的女孩在学校音乐室弹电吉他”。EasyRef将处理这些参考图像和文本提示,生成一张融合了所有参考元素和风格的视觉一致的图像。这种方法不仅能够捕捉到梵高的风格特点,还能够确保女孩、电吉他和音乐室等元素在最终生成的图像中得到体现。

EasyRef的创新之处
多模态大语言模型(MLLM)的利用:
- 多图像理解和指令跟随能力:EasyRef利用了MLLM的强大多模态理解能力,特别是其处理多个图像并根据指令捕捉一致视觉元素的能力。通过提示MLLM,系统可以根据指令从多个参考图像中提取出一致的视觉特征。
- 指令驱动的视觉元素捕捉:用户可以通过自然语言指令告诉模型关注哪些视觉元素,例如“捕捉所有图像中的建筑风格”或“保持人物的姿态一致”。这种指令驱动的方式使得模型能够更灵活地应对不同场景的需求。
适配器机制:
- MLLM表示注入扩散过程:为了将MLLM提取的视觉特征有效地融入扩散模型的生成过程中,EasyRef引入了一个适配器机制。该适配器将MLLM的表示注入到扩散模型的中间层,从而影响生成过程。这种方式不仅提高了生成结果的质量,还使得模型能够轻松推广到未见领域,挖掘未见数据中的一致视觉元素。
高效的参考聚合策略:
- 减轻计算成本:为了减少计算开销,EasyRef引入了一种高效的参考聚合策略。该策略能够在不牺牲质量的前提下,快速聚合多个参考图像的特征,确保生成过程的高效性。
- 细粒度细节保留:通过优化聚合策略,EasyRef能够在捕捉全局一致性的同时,保留更多的细粒度细节,使得生成的图像更加逼真和多样化。
渐进式训练方案:
- 逐步提升模型性能:EasyRef采用了一种渐进式的训练方案,逐步增加参考图像的数量和复杂性。这种训练方式不仅有助于模型更好地学习多个图像中的一致元素,还能提高其在不同场景下的泛化能力。
MRBench:新的多参考图像生成基准
为了评估EasyRef的性能,研究人员引入了MRBench,这是一个全新的多参考图像生成基准。MRBench涵盖了多种生成任务,包括但不限于:
- 跨领域生成:测试模型在不同领域(如风景、人物、建筑等)之间的零样本泛化能力。
- 美学质量评估:通过人类评价和自动指标评估生成图像的美学质量。
- 一致性验证:验证生成图像是否成功捕捉了多个参考图像中的一致视觉元素。
工作原理
EasyRef的工作流程包括以下几个关键步骤:
- 预训练扩散模型:用于条件图像生成。
- 预训练多模态LLM:用于编码一组参考图像和文本提示。
- 条件投影器:将MLLM的表示映射到扩散模型的潜在空间。
- 可训练适配器:将图像条件嵌入整合到扩散过程中。
具体来说,EasyRef通过MLLM处理参考图像和文本提示,然后将MLLM的表示通过适配器注入到扩散模型中,以此来生成与参考图像和文本提示一致的图像。

实验结果
实验结果表明,EasyRef在美学质量和跨不同领域的鲁棒零样本泛化方面超越了现有的无需调优方法(如IP-Adapter)和基于调优的方法(如LoRA)。具体来说:
- 美学质量:EasyRef生成的图像在视觉上更加美观,细节更加丰富,尤其是在捕捉多个参考图像中的一致元素方面表现出色。
- 零样本泛化:EasyRef能够在未见过的领域中保持良好的生成效果,展示了其强大的泛化能力。
- 计算效率:相比于基于调优的方法,EasyRef的计算成本显著降低,同时保持了高质量的生成结果。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











