Snap推出新架构注意力混合(Mixture-of-Attention,简称MoA),即在个性化图像生成中实现主体与上下文解耦的注意力混合模型(MoA),用于个性化文本到图像的扩散模型。简单来说,MoA是一种新的架构,它可以让AI模型根据用户的个性化需求生成包含特定人物的图像,同时保持原有模型的风格和多样性。
- 项目主页:https://snap-research.github.io/mixture-of-attention
- GitHub:https://github.com/snap-research/mixture-of-attention
该架构的设计灵感来源于大语言模型中广泛应用的混合专家(Mixture-of-Experts)机制。MoA通过两条注意力路径来分配生成任务:一条是个性化分支,另一条是非个性化的先验分支。MoA旨在通过固定先验分支中的注意力层来保留原始模型的先验知识,同时,个性化分支在生成过程中进行最小程度的干预,学习将主体嵌入到由先验分支生成的布局和上下文中。Snap开发了一种新颖的路由机制,负责在每层中管理像素在这两条分支之间的分配,以优化个性化内容和通用内容的融合。一旦训练完成,MoA能够创建出高质量、个性化的图像,这些图像包含多个主体,且其构图和交互方式与原始模型生成的图像一样丰富多样。尤为重要的是,MoA显著增强了模型原有能力与新增个性化干预之间的区分度,从而提供了更为清晰的主体与上下文控制,这在以前是难以实现的。

主要功能和特点:
- 个性化生成:MoA能够将用户提供的人物图像与文本提示结合起来,生成包含这些人物的个性化图像。
- 主体与上下文解耦:MoA能够区分图像中的主体(人物)和上下文(背景),允许用户更改图像中的主体,而不会影响背景或其他元素。
- 保持多样性:即使在个性化生成中,MoA也能够保持图像的多样性,生成与原始模型风格一致的图像。
- 快速生成:MoA的设计允许快速迭代和生成图像,无需针对新主体进行优化。
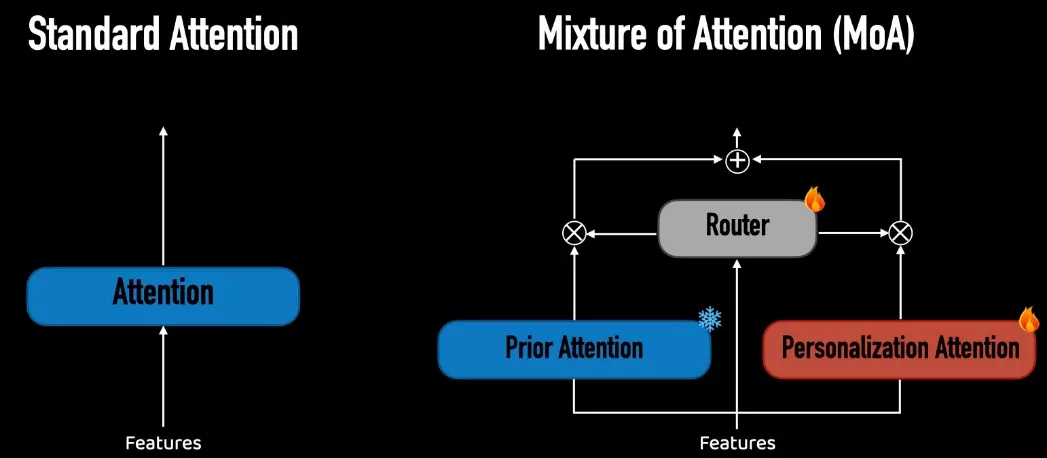
工作原理:
MoA架构由两个注意力路径组成:一个个性化分支和一个非个性化(固定)分支。个性化分支学习将输入图像中的主体嵌入到由非个性化分支生成的布局和上下文中。非个性化分支固定不变,保留了原始模型的先验知识。此外,MoA还有一个路由机制,它管理每个层级像素在这两个分支之间的分布,以优化个性化和通用内容创建的混合。
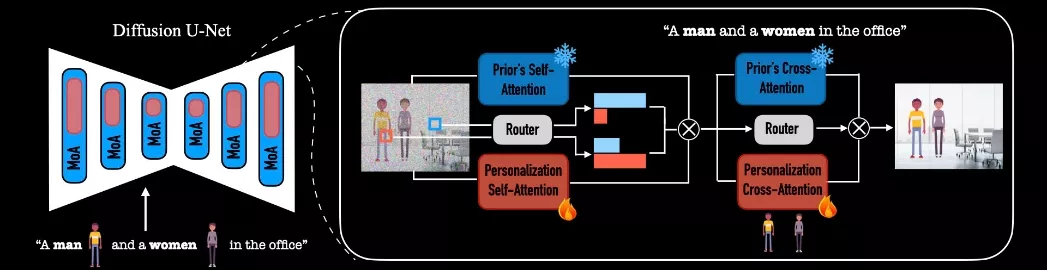
具体应用场景:
- 个性化图像创作:用户可以要求生成包含自己或朋友的照片,例如“创建一张我和我的朋友在巴黎埃菲尔铁塔前握手的照片”。
- 多主体图像:MoA能够处理包含多个人物的图像生成,适用于如家庭合影、团队照片等场景。
- 图像编辑:MoA与现有的基于扩散模型的图像编辑技术兼容,可以用于真实照片中的人物替换或风格转换。
- 故事叙述:在需要讲述故事的应用中,MoA可以帮助生成一致的角色,并在不同的场景中使用这些角色。
通过一系列实验展示了MoA在处理遮挡、不同身体形态的人物图像生成以及多人物场景中的有效性。此外,MoA的设计使其能够与现有的图像生成和编辑技术无缝集成,为个性化图像生成提供了新的可能性。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...