
Stability AI于北京时间2023年 7 月 27 日正式发布 Stable Diffusion XL 首个正式版 1.0,SDXL 1.0 能生成更加鲜明准确的色彩,在对比度、光线和阴影方面做了增强,可生成 100 万像素的图像(1024 x 1024),直接对标Midjourney。

Stable Diffusion XL(SDXL)1.0 的基础模型拥有 35 亿个参数,模型组合管线则高达 66 亿个参数,其优化器(refiner)能为基础模型产出图片加入更准确的色彩、更高对比及更多细节,Stability AI也强化微调、定制化功能,让用户可用最少 5 张图片就能针对特定人士、产品或物件定制图片。
Stability AI的最佳图像模型
SDXL 1.0是Stability AI的旗舰图像模型,也是用于图像生成的最佳开源模型。我们已经将它与其他各种模型进行了对标测试,结果是明确的——人们更喜欢SDXL 1.0生成的图像,而不是其他开源模型。这项研究结果来自数周的偏好数据,这些数据是从我们在Discord上的实验模型的生成以及外部测试中捕获的。
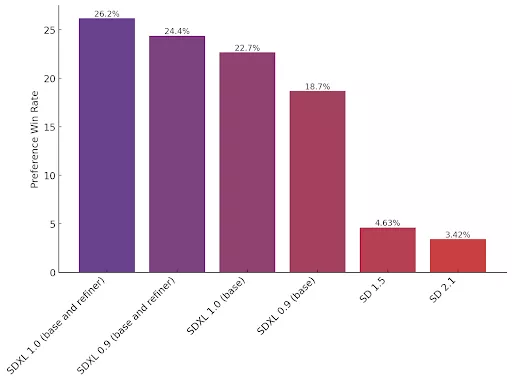
针对具有挑战性的概念和风格的更好艺术品
SDXL几乎可以生成任何艺术风格的高质量图像,并且是用于照片级写实的最佳开源模型。可以提示生成不同的图像,而无需模型赋予任何特定的“感觉”,从而确保风格的绝对自由。SDXL 1.0 特别针对鲜艳和准确的颜色进行了调整,与前代相比,对比度、光照和阴影效果更好,所有这些都在原生 1024x1024 分辨率下完成。
此外,SDXL可以生成对图像模型来说难以渲染的概念,例如手和文本或空间排列的构图(例如,背景中一个女人在追逐前景中的一只狗)。

更智能,提示词更简单
SDXL只需几个单词即可创建复杂、详细且美观愉悦的图像。用户不再需要调用诸如“杰作”之类的限定词来获得高质量的图像。此外,SDXL可以理解“红场”(一个著名的地方)与“红色正方形”(一个形状)之类的概念之间的差异。

最大的开源图像模型
SDXL 1.0 拥有任何开源图像模型中最大的参数计数之一,拥有一个 35 亿参数的基础模型和一个 66 亿参数的模型集成管道(最终输出是通过在两个模型上运行并聚合结果创建的)。
完整模型由用于潜在扩散的专家混合管道组成:在第一步中,基本模型生成(嘈杂的)潜在变量,然后使用专门针对最终去噪步骤的优化模型对这些潜在变量进行进一步处理。请注意,基本模型也可以用作独立模块。
这种两阶段架构允许在不影响速度或不需要过多的计算资源的情况下,在图像生成中实现鲁棒性。SDXL 1.0应该可以在具有8GB 显存的消费级GPU或现成的云实例上有效工作。
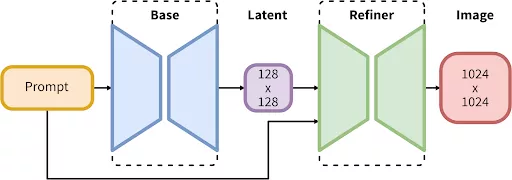
微调和高级控制
使用 SDXL 1.0,对模型进行微调以适应自定义数据比以往任何时候都更容易。可以生成自定义的 LoRAs 或检查点,而无需进行大量的数据处理。Stability AI 团队正在构建下一代针对特定任务的结构、风格和构图控制,为 SDXL 专门设计的 T2I / ControlNet。

模型下载地址:
- SDXL-refiner-1.0: https://huggingface.co/stabilityai/stable-diffusion-xl-refiner-1.0
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...











