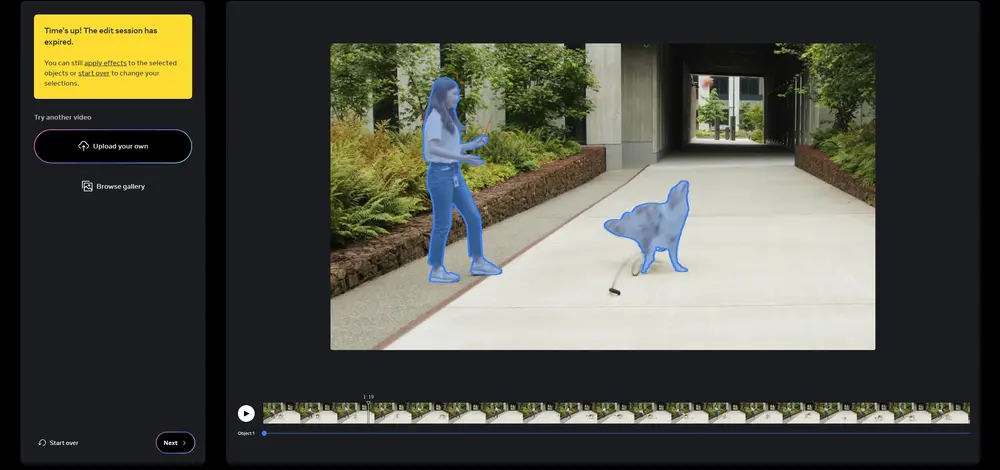
Meta在去年推出了图像分割模型Segment Anything,今年它们又推出了升级版Segment Anything Model 2 (SAM 2),这是一种用于图像和视频中可提示视觉分割的基础模型,旨在解决图像和视频中的可提示视觉分割问题。Meta将 SAM 适应于视频领域,通过将图像当作只有单帧的视频来处理。模型设计采用了一种具备流式内存的简单 Transformer 架构,用于实时视频处理。Meta构建了一个模型-数据循环引擎,通过用户互动不断优化模型和数据,以此来构建了Meta的 SA-V 数据集——截至目前为止规模最大的视频分割数据集。在Meta的数据上训练的 SAM 2 在多种任务和不同的视觉领域中展现出了强大的性能。
- 项目主页:https://ai.meta.com/sam2
- GitHub:https://github.com/facebookresearch/segment-anything-2
- Demo:https://sam2.metademolab.com
- HF Demo:https://huggingface.co/spaces/SkalskiP/segment-anything-model-2
例如,你手里有一堆照片和视频,你想要从中把某个特定的物体或人物单独“抠”出来,就像是用剪刀剪出来一样。这个过程在计算机视觉领域被称为“图像和视频分割”,SAM 2就是专门干这个活儿的一个智能模型。
主要功能
- 图像分割:SAM 2能够识别并分割出图片中的单个物体,比如从风景照片中分割出一棵树或一只动物。
- 视频分割:更厉害的是,它还能处理视频,跟踪并分割视频中移动的物体,比如在一系列连续的汽车追逐镜头中,始终识别并分割出同一辆车。

主要特点
- 实时处理:SAM 2设计得非常高效,能够实时处理视频,这意味着它不需要花很长时间就能给出结果。
- 用户交互:它可以通过用户的简单提示(比如点击或画框)来学习和改进其分割结果,这使得它非常灵活和用户友好。
- 数据驱动:SAM 2的训练依赖于大量的视频数据,这些数据通过一个智能的“数据引擎”收集和生成,这个引擎能够与标注者互动,生成高质量的训练数据。
工作原理
SAM 2的核心是一个“变压器”架构,这是一种在深度学习中常用的模型类型。它利用一种叫做“流式记忆”的技术来处理视频。简单来说,它就像是一个有记忆的智能体,能够记住之前看到的内容,并用这些记忆来帮助理解新的视频帧。
- 图像编码器:首先,模型会分析每一帧图像,提取出关键的视觉特征。
- 记忆注意力:然后,模型会利用之前帧的记忆来增强当前帧的理解,这就像是它在看视频时能够记住之前发生的事情。
- 提示编码器和掩码解码器:用户可以通过点击或画框来提供提示,模型会根据这些提示来生成分割掩码,即物体的轮廓。
- 记忆编码器和记忆库:模型会将预测的掩码存储在记忆库中,以便在处理后续帧时使用,这有助于保持物体跟踪的连续性。
具体应用场景
- 增强现实/虚拟现实:在这些应用中,SAM 2可以帮助识别和分割虚拟环境中的物体,提供更自然的交互体验。
- 自动驾驶:在自动驾驶系统中,SAM 2可以用来实时识别和跟踪道路上的其他车辆或行人,提高安全性。
- 视频编辑:在视频制作中,SAM 2可以快速分割出视频中的特定物体,方便进行特效添加或内容编辑。
- 医学成像:在医学领域,SAM 2可以帮助医生从复杂的医学图像中分割出感兴趣的区域,比如肿瘤或器官。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...