
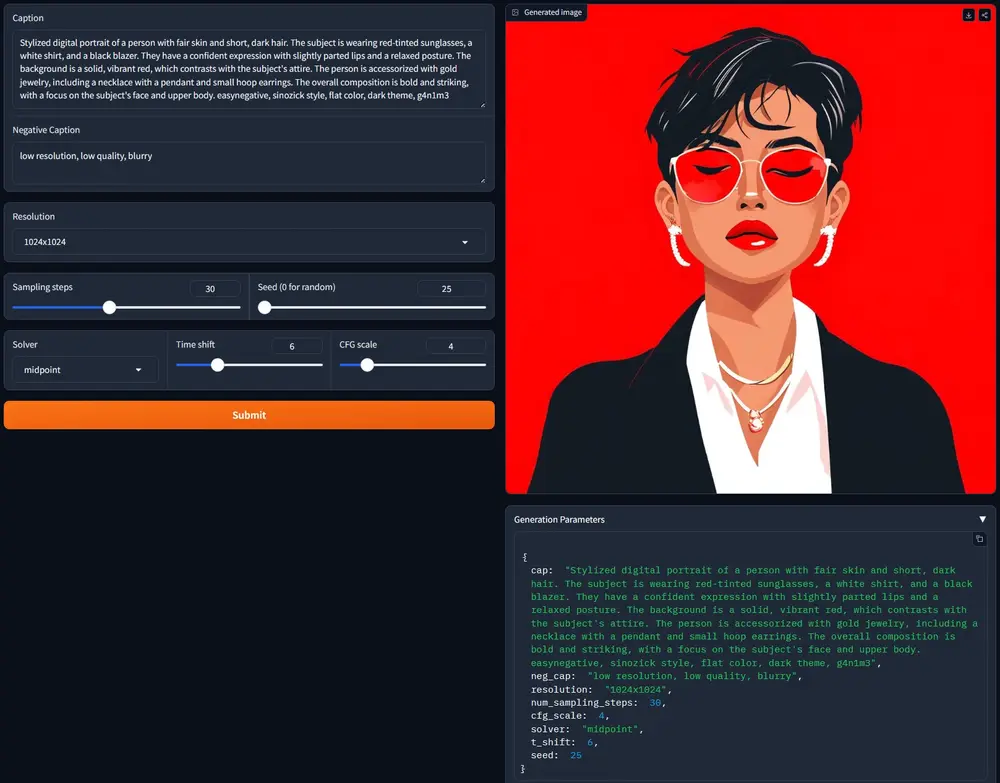
上海人工智能实验室和香港中文大学的研究人员推出新型多模态自回归模型Lumina-mGPT,它能够执行各种视觉和语言任务,尤其擅长根据文本描述生成逼真的图片。与现有的基于自回归的图像生成方法不同,Lumina-mGPT采用了一个预训练的解码器仅变换器(decoder-only transformer)作为统一框架,用于建模多模态Token序列。例如,你只需用文字描述你想要的图片内容,比如“一只坐在草地上的小猫”,Lumina-mGPT就能根据你的描述生成一张逼真的图片。这就像是拥有一个能够读懂你想法的魔法画笔。
- GitHub:https://github.com/Alpha-VLLM/Lumina-mGPT
- 模型:https://huggingface.co/collections/Alpha-VLLM/lumina-family-66423205bedb81171fd0644b
- Demo:https://huggingface.co/spaces/Alpha-VLLM/Lumina-Next-T2I
Lumina-mGPT关键见解是,一个简单的解码器-only Transformer 结合多模态生成预训练 (mGPT),利用在大规模交错的文本-图像序列上的下一个令牌预测目标,可以学习到广泛的多模态能力,从而实现逼真的文本到图像生成。基于这些预训练模型,研究团队提出了灵活渐进监督微调 (FP-SFT) 方法,在高质量的图像-文本对上进行训练,以充分释放其在任何分辨率下合成高审美图像的潜力,同时保持其通用的多模态能力。此外,研究团队引入了全能监督微调 (Omni-SFT),将 Lumina-mGPT 转变为一个基础模型,无缝实现全能任务统一。最终的模型展示了多样化的多模态能力,包括视觉生成任务如灵活的文本到图像生成和可控生成,视觉识别任务如分割和深度估计,以及视觉语言任务如多轮视觉问答。
主要功能
- 文本到图像生成:根据用户的文本描述生成相应的图片。
- 多模态任务统一:除了图像生成,Lumina-mGPT还能执行如图像分割、深度估计和多轮视觉问答等多模态任务。
主要特点
- 预训练模型:Lumina-mGPT基于一个预训练的多模态生成预训练(mGPT)模型,这使得它能够利用大规模混合文本-图像数据集中的丰富知识。
- 灵活的高分辨率解码:模型能够生成任意分辨率的高清晰度图片。
- 多任务泛化能力:通过多模态预训练,Lumina-mGPT展示了在多种任务上的泛化能力。
工作原理
- 多模态预训练:使用大规模的文本-图像数据对进行预训练,学习文本和图像之间的关联。
- 解码器仅变换器:采用一个解码器仅的自回归变换器来处理文本编码和图像Token解码。
- 灵活的进度式监督微调(FP-SFT):在预训练基础上,通过逐步增加图像分辨率的方式进行微调,以生成高分辨率的图片。
- 全任务统一的监督微调(Omni-SFT):将模型进一步微调,以支持多种不同的任务。

具体应用场景
- 艺术创作:艺术家可以使用Lumina-mGPT生成概念艺术图或插图。
- 媒体和广告:在设计广告或制作媒体内容时,快速生成吸引人的视觉内容。
- 教育和培训:生成教学材料中的图解或图表,帮助解释复杂的概念。
- 娱乐和游戏:在游戏中生成环境或角色的视觉内容。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











