
AI2、加州大学欧文分校和华盛顿大学的研究人员介绍了一种名为OneDiffusion的多功能、大规模扩散模型。OneDiffusion能够无缝支持在多样化任务中进行双向图像合成和理解,涵盖从文本、深度、姿势、布局和语义图等输入条件生成图像,到图像去模糊、放大以及深度估计和分割等反向过程。此外,OneDiffusion还支持多视图生成、相机姿态估计,以及使用顺序图像输入的即时个性化。
- 项目主页:https://lehduong.github.io/OneDiffusion-homepage
- GitHub:https://github.com/lehduong/OneDiffusion
- 模型:https://huggingface.co/lehduong/OneDiffusion
OneDiffusion模型的设计目标是成为一个通用的视觉模型,能够像大型语言模型(如GPT-4)一样,在不同领域执行广泛的任务,而无需特定任务的模块,并且能够在零样本学习中处理未明确训练的任务。OneDiffusion可以应用到多个应用场景,例如:
文本到图像合成(Text-to-Image Synthesis):根据文本提示生成高质量的图像,如“一个秋天的森林中,一只火红的、有着莫霍克发型的松鼠”。 图像理解(Image Understanding):从图像中检测物体、估计深度、估计姿态等,例如从一张手的图片中估计手的姿态。 多视角生成(Multi-view Generation):根据单一视角的输入图像生成多个视角的图像,如从一张正面图像生成不同角度的视角。

主要功能:
OneDiffusion模型的主要功能包括:
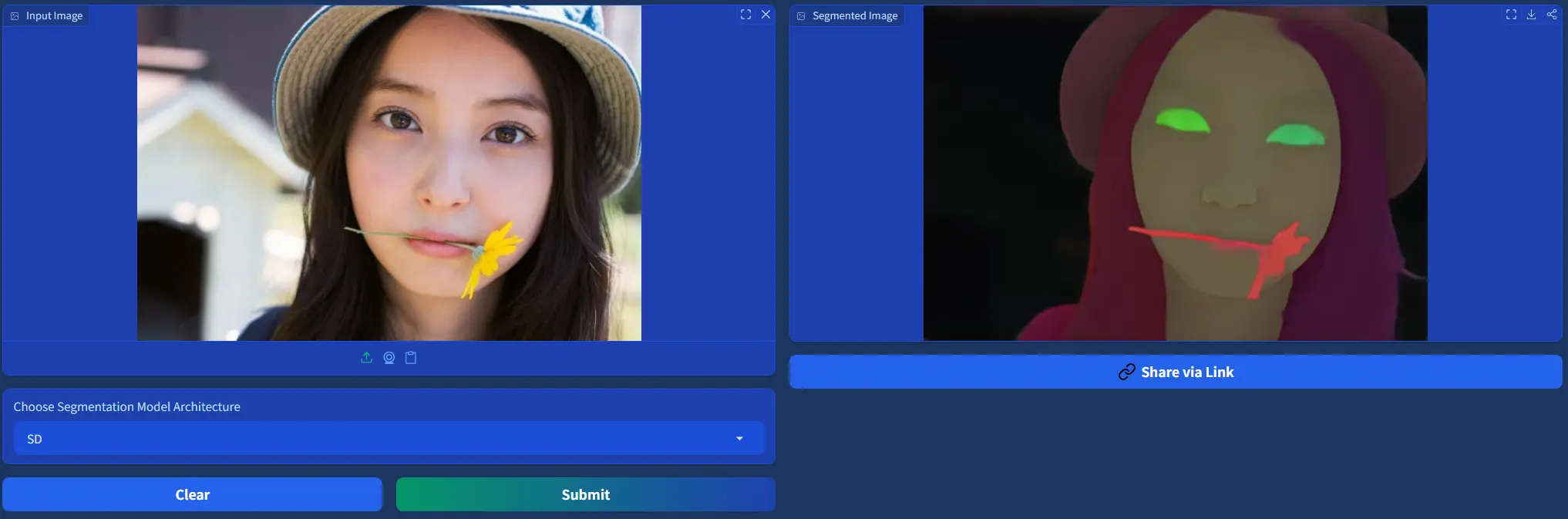
条件图像生成:从文本、深度、姿态、布局和语义图等输入生成图像。 图像理解任务:如图像去模糊、上采样以及深度估计和分割等反向过程。 多视角生成:根据相机姿态估计和即时个性化使用序列图像输入生成图像。 个性化定制(ID Customization):使用一系列图像作为条件输入进行个性化生成。
主要特点:
统一架构:OneDiffusion采用统一的架构来处理多种图像合成任务,无需外部插件或损失函数。 双向能力:模型支持从图像到文本和从文本到图像的双向任务。 灵活性:能够适应任何分辨率,增强了泛化和可扩展性。 多任务训练:通过One-Gen数据集,模型能够跨多个任务进行联合训练。
工作原理:
OneDiffusion模型的工作原理基于流匹配(Flow matching)框架,通过学习一个时间依赖的向量场来转换两个概率分布。在训练期间,所有条件和目标图像被建模为一系列“视图”,这些视图在训练时具有不同的噪声水平。在推理时,任何视图都可以用作条件输入,或者设置为噪声以生成输出图像。这种设置允许动态配置生成过程,支持跨多种生成任务的灵活应用。
技术细节
1、训练方法:
噪声尺度:通过在训练过程中引入不同噪声尺度的帧序列,使得模型能够适应多种任务。 条件图像:任何帧在推理时都可以作为条件图像,增强了模型的灵活性和适应性。
2、模型架构:
统一框架:采用统一的训练框架,消除了对专用架构的需求,支持多任务训练。 分辨率适应:模型能够平滑地适应不同分辨率的输入,增强了泛化能力。
实验结果
尽管训练数据集相对较小,OneDiffusion在多个生成和预测任务中展现了具有竞争力的性能:
文本到图像:生成的图像与文本描述高度一致,细节丰富且自然。 多视图生成:能够从不同视角生成高质量的图像,保持对象的一致性和场景的真实感。 ID保留:在生成过程中保留了输入图像的身份特征,适用于人脸生成等任务。 深度估计:生成的深度图准确反映了场景的三维结构。 相机姿态估计:能够准确估计相机的姿态,适用于AR/VR等应用场景。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
![黑森林实验室正式发布图像编辑模型FLUX.1 Kontext [dev]](https://pic.sd114.wiki/wp-content/uploads/2025/06/1750964036-1750964036-FLUX.1-Kontext-2.webp~tplv-o4t1hxlaqv-image.image)

暂无评论...











