
Qwen2vl-Flux 是一种先进的跨模态图像生成模型,它将Qwen2VL的视觉语言理解能力与FLUX框架相结合,实现了更精确和上下文感知的图像生成。该模型在文本提示和视觉参考的基础上生成高质量图像,提供了卓越的跨模态理解和控制。此模型采用采用MIT许可证。

- GitHub:https://github.com/erwold/qwen2vl-flux
- 模型:https://huggingface.co/Djrango/Qwen2vl-Flux
- Demo:https://huggingface.co/spaces/Djrango/qwen2vl-flux-mini-demo
模型架构
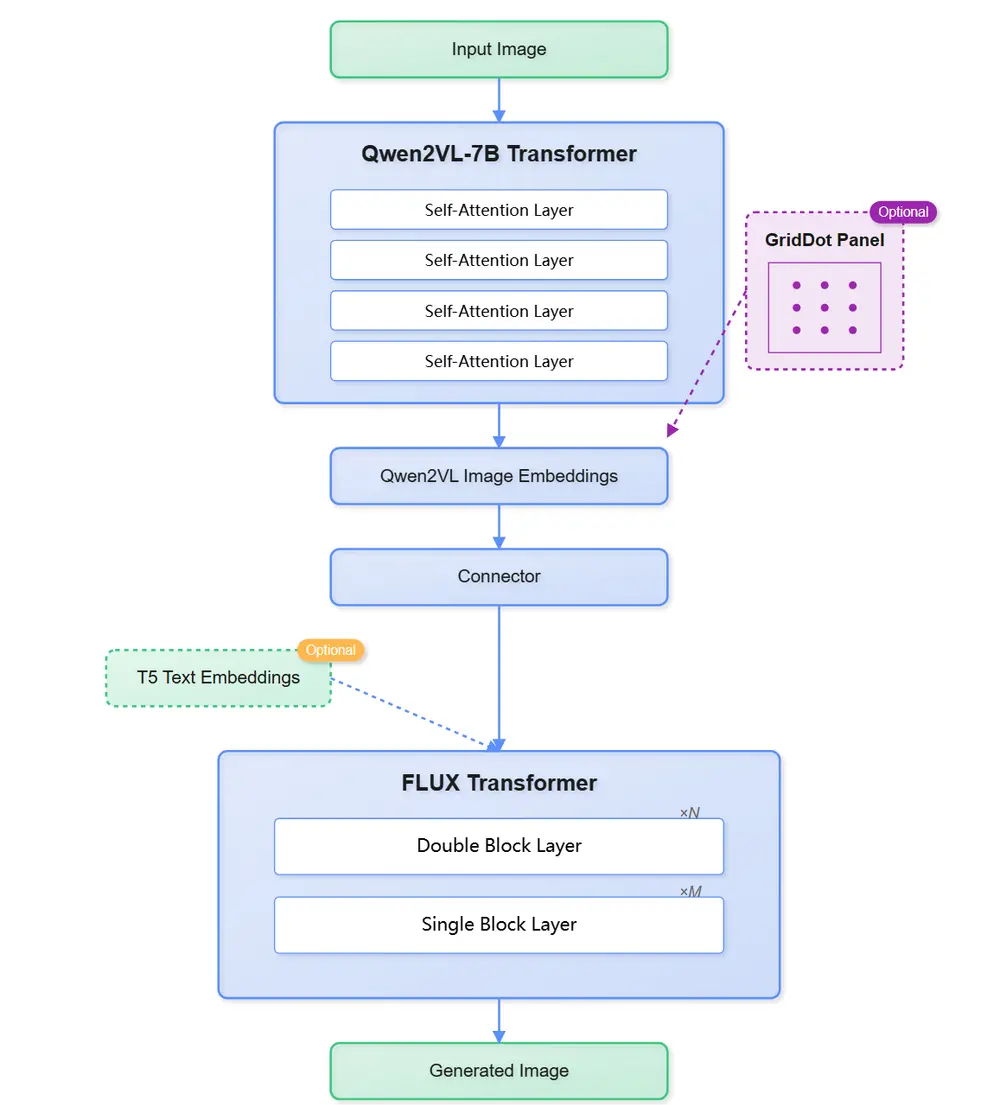
Qwen2vl-Flux通过使用视觉-语言模型(Qwen2VL)替换传统的文本编码器,从而实现了更卓越的多模态理解和生成能力。
Qwen2vl-Flux 的核心架构包括以下几个关键组件:
视觉语言理解模块(Qwen2VL):利用Qwen2VL的强大视觉语言理解能力,实现对文本和图像的深度解析。 增强的FLUX骨干:基于FLUX框架的深度学习模型,增强了图像生成的精度和效率。 多模式生成管道:支持多种生成模式,包括图像变体生成、图像到图像转换、图像修复和控制网引导生成。 结构控制集成:集成了深度估计和线条检测技术,实现对生成图像结构的精确控制。
功能
- 利用Qwen2VL实现卓越的跨模态理解,能够准确解析文本提示和视觉参考。
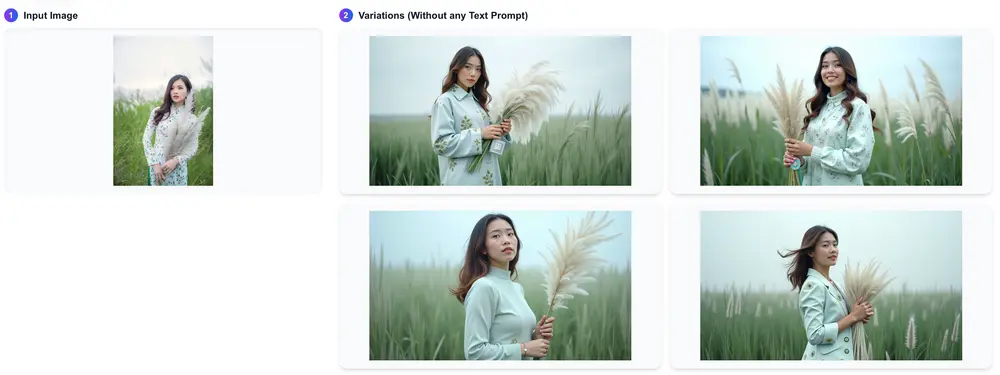
- 图像变体生成:创建多样化的图像变体,同时保持原始图像的本质。
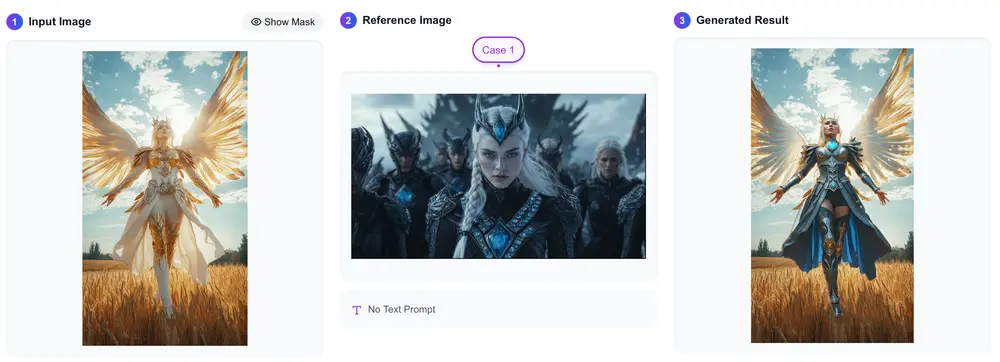
- 图像到图像转换:将一张图像转换为另一种风格或类型。
- 图像修复:修复图像中的损坏部分或缺失内容。
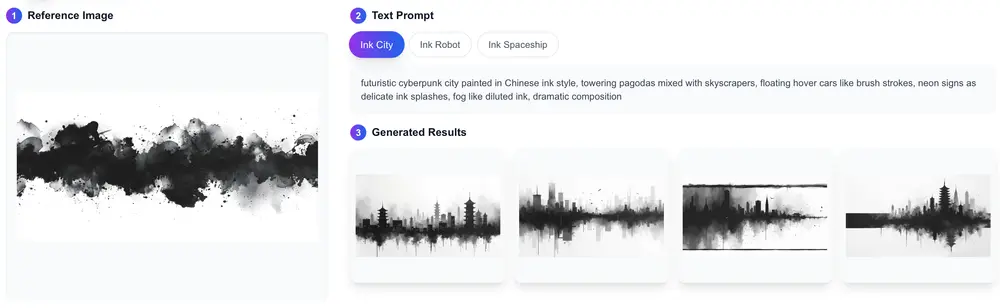
- 控制网引导生成:通过控制网引导生成过程,实现更精确的图像生成。
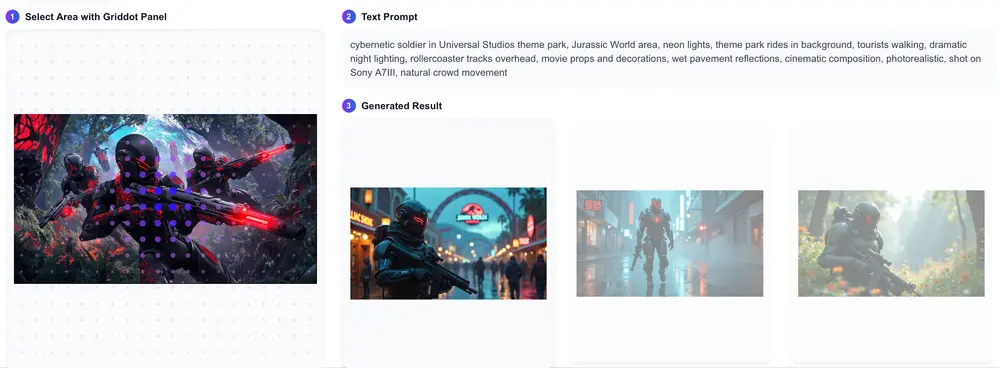
- 集成深度估计和线条检测技术,实现对生成图像结构的精确控制,确保生成图像的结构合理性和一致性。
- 支持通过空间注意力控制进行聚焦生成,使生成的图像更加符合用户的需求和期望。
- 支持多种宽高比,最高可达1536x1024,提供高分辨率的图像输出。
技术规格
框架:PyTorch 2.4.1+ 基础模型: FLUX.1-dev Qwen2-VL-7B-Instruct
内存需求:48GB+ VRAM 支持的图像尺寸: 1024x1024 (1:1) 1344x768 (16:9) 768x1344 (9:16) 1536x640 (2.4:1) 896x1152 (3:4) 1152x896 (4:3)
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











