
Stability AI因为Stable Diffusion 3 Medium模型的许可证问题备受诟病,虽然后来更改了许可证,但此模型在人物尤其是躺倒后人物的糟糕表现还是不受开源社区待见。不少人开始转向同是DiT模型的腾讯混元大模型Hunyuan-DiT和PixArt模型PIXART-Σ,昨天 Fal.ai平台推出了新的开源DiT架构模型AuraFlow,此模型与SD一样是MMDiT架构,书写英文的能力优秀。此模型比较大,不太适合在本地运行,不过官方已表示目前模型还是初始版本,之后会推出迷你版本,适合本地使用,目前该模型已经支持 ComfyUI 和 Diffusers。

- 模型地址:https://huggingface.co/fal/AuraFlow
- Demo:https://huggingface.co/spaces/multimodalart/AuraFlow
- fal地址:https://fal.ai/models/fal-ai/aura-flow
官方发布的技术细节
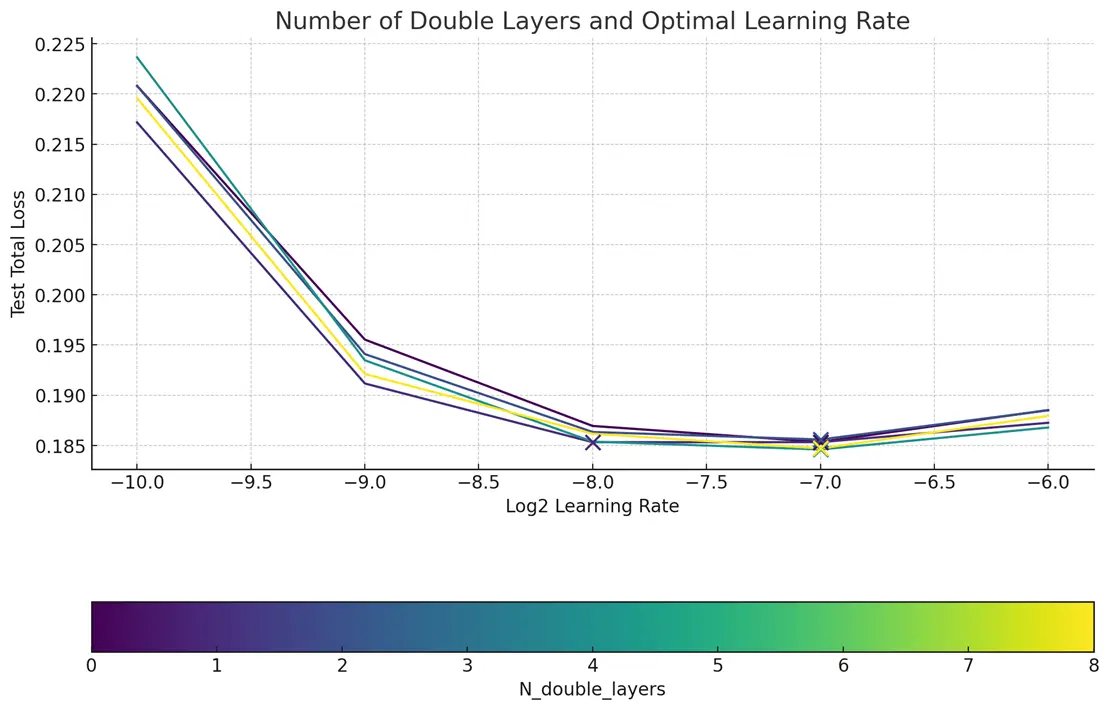
MFU(模型吞吐量)作为核心优化目标
多数层无需配备MMDiT模块:虽然MMDiT在性能上有杰出表现,我们发现,大幅简化结构至单一DiT模块,不仅提升了可扩展性,还使得模型训练更加高效。通过小规模原型的精心调整,我们大量移除了MMDiT模块,代之以扩增的DiT编码器模块。这一改变在6.8亿参数级别上,将模型的计算效率提高了15%。
借助torch.compile强化训练过程:在fal,我们早已成为Torch Dynamo与Inductor的强大支持者,并在此基础之上(配合定制的Dynamo后端),以超高速度和高硬件利用率执行推理任务。鉴于PT2的torch.compile能全面优化前向和反向传播,我们进一步利用其针对每一层前向传播方法的基本单元,对AuraFlow的训练流程进行了微调,进而根据阶段的不同,额外提升了MFU约10%到15%。
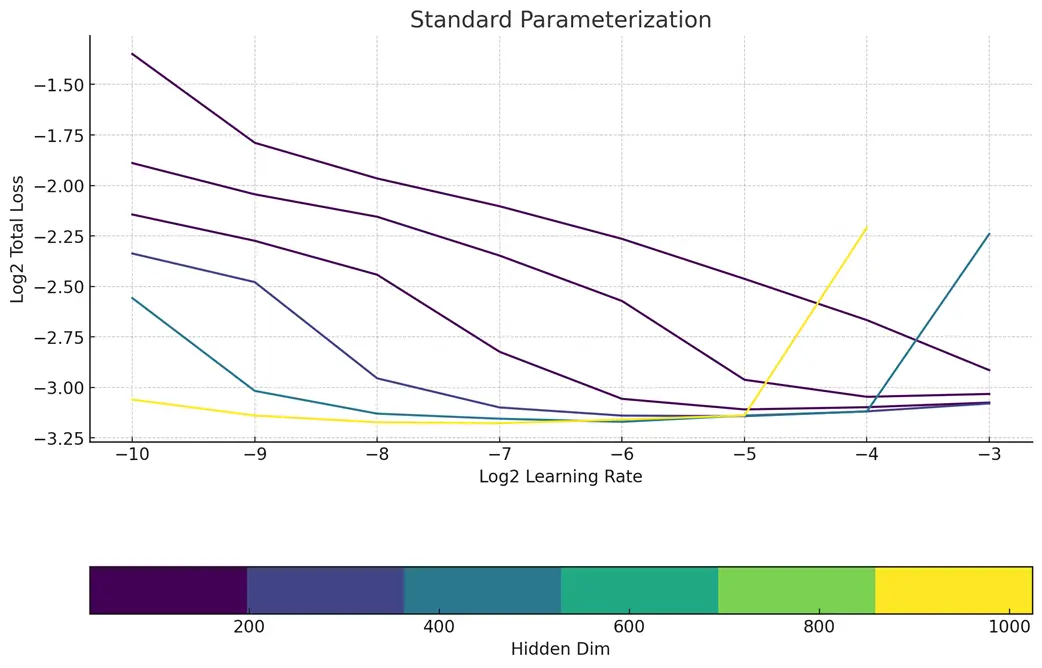
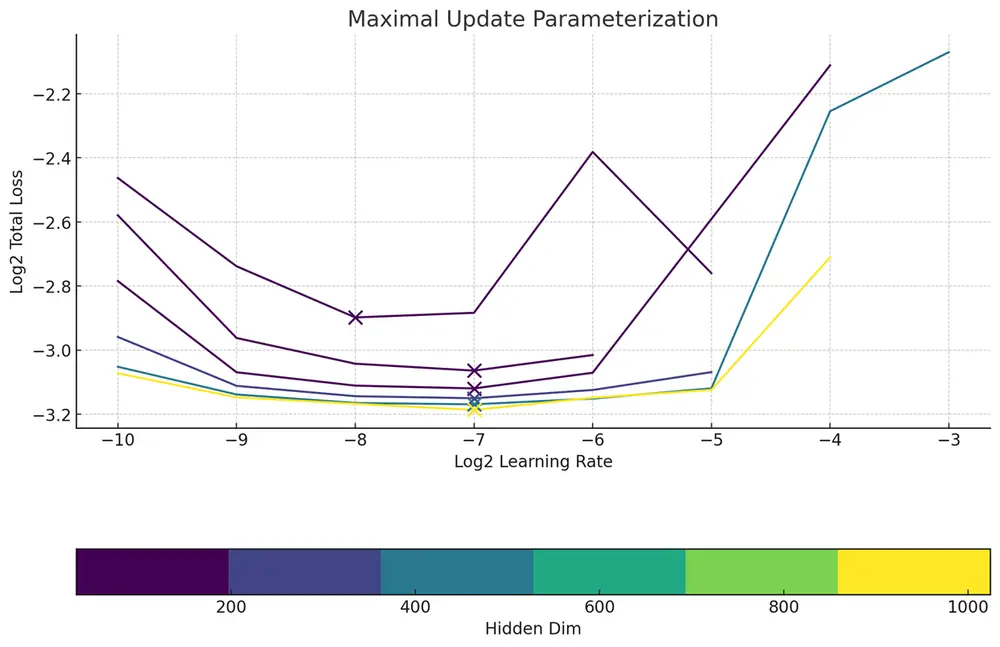
实现零样本学习率迁移
我们虽非Meta,但仍追求无需广泛调整即可获得优异超参数的效果。令人欣喜的是,我们观察到当应用最大更新参数化(muP)时,MMDiT架构同样支持零样本学习率直接迁移。相较于其他方案,muP在大规模设置下学习率的可预测性方面展现出了明显优势。
全部重新标注
重新标注所有内容是确保数据集中没有错误文本条件的常用技巧。我们使用我们的内部标注器和外部标注的数据集来训练这些模型,这显著提高了遵循指令的质量。我们极端地遵循了 DALL·E 3 的方法,并且我们没有任何 alt-texts 的标题。
拓宽架构,缩短路径,追求卓越!
为了深入探索最理想的架构设计,我们致力于构建更“厚实”的模型,即让模型架构能够充分利用最大维度为256的矩阵乘法。这促使我们在muP确定的最佳学习率指导下,探寻最优的宽高比。研究证实,在大规模场景下,宽高比介于20至100之间最为适宜,这与《自回归生成模型的规模定律( Scaling Laws for Autoregressive Generative Modeling)》的研究结论相吻合。最终,我们采用了3072/36的比例设定,造就了一个规模达68亿参数的模型。
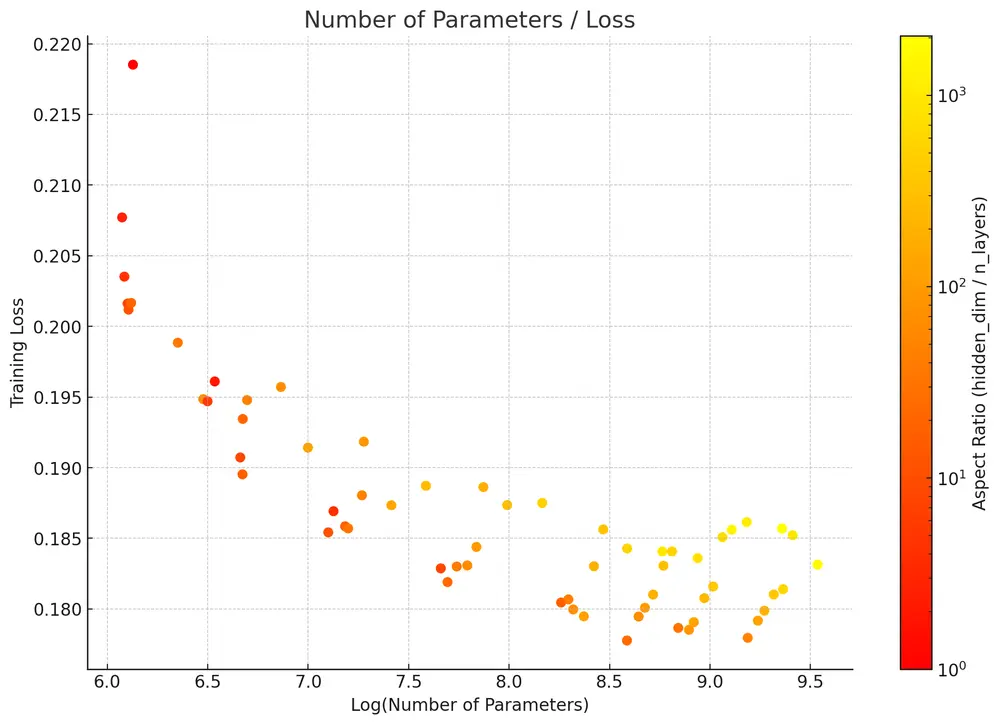
总结而言,我们竭尽全力优化并精准定位了大规模训练的理想配置。基于以上发现,我们成功在四周期的计算资源内,从头开始,在我们最顶级的配置下,完成了包含256x256、512x512、1024x1024分辨率预训练及宽高比微调的文本到图像模型训练。模型在预训练阶段的GenEval评估得分达到了0.63至0.67,而经过1024x1024分辨率预训练后,得分相近,约为0.64。然而,通过类似于DALL·E 3的提示增强流程,我们进一步提升到了0.703的高分!
如何更好的书写提示词
提示词是一种描述图像的方式,必要时可以用逗号分隔。所有字母均为小写。在不改变原始提示中披露的物体间相对位置、互动、颜色或其他特定属性的前提下,将下面的输入扩展为更详细的说明。请明确位置信息、颜色、物体数量、其他视觉方面及特征。务必包含尽可能多的细节。务必描述图像中所见的空间关系,可以使用诸如“左/右”、“上/下”、“前/后”、“远/近/相邻”、“内部/外部”等词语。务必包含物体间的互动描述,如“一张桌子放在厨房锅具的前面”和“桌上有篮子”。同时描述图像中物体的相对大小。当图像中有人物时,务必包含显著物体的数量。如果是摄影作品,请在合理时包含如散景、大视野等摄影细节,避免仅为提及而提及。若是艺术品,则包含如极简主义、印象派、油画等风格细节。如适宜,可融入世界及时代背景知识,如“1950年代的雪佛兰汽车”等。
下一步计划?
目前该模型还没有完成最终训练,此次推出的是0.1版本,这次发布的版本是初次亮相,目的是启动社区的参与。对于大多数消费者显卡来说,不足以在本地运行此模型,官方表示将推出一个更小但效率更高的模型版本。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











