
来自香港大学和TikTok的研究人员推出单目深度估算模型Depth Anything的升级版Depth Anything V2,让计算机通过分析单张图片来预测物体距离的技术,这在自动驾驶、3D建模和虚拟现实等领域有着重要应用。研究团队新的评估基准DA-2K,这个基准包含精确的注释和多样化的场景,用于评估深度估计模型的性能,推动未来研究的发展。(相关:深度估算模型Depth Anything:让照片自动感知空间距离)
- 项目主页:https://depth-anything-v2.github.io
- 模型地址:https://huggingface.co/depth-anything
- Demo:https://huggingface.co/spaces/depth-anything/Depth-Anything-V2
- ComfyUI插件:https://github.com/kijai/ComfyUI-DepthAnythingV2
相较于V1版,V2版本通过三项核心策略实现了更细腻、更稳健的深度预测:1) 用合成图像全面替代了所有标记的真实图像;2) 扩大了教师模型的容量;3) 利用了大规模伪标记的真实图像作为媒介来训练学生模型。与近期基于Stable Diffusion技术构建的顶级模型对比,Depth Anything V2在效率上实现了显著提升(速度快了不止10倍),并且精度更高。研究团队提供了多种规模的模型(参数量跨度从2500万至13亿),以满足各类应用场景需求。凭借其出色的泛化能力,研究团队进一步通过加入度量深度标签对这些模型进行了微调,形成了我们的度量深度模型系列。
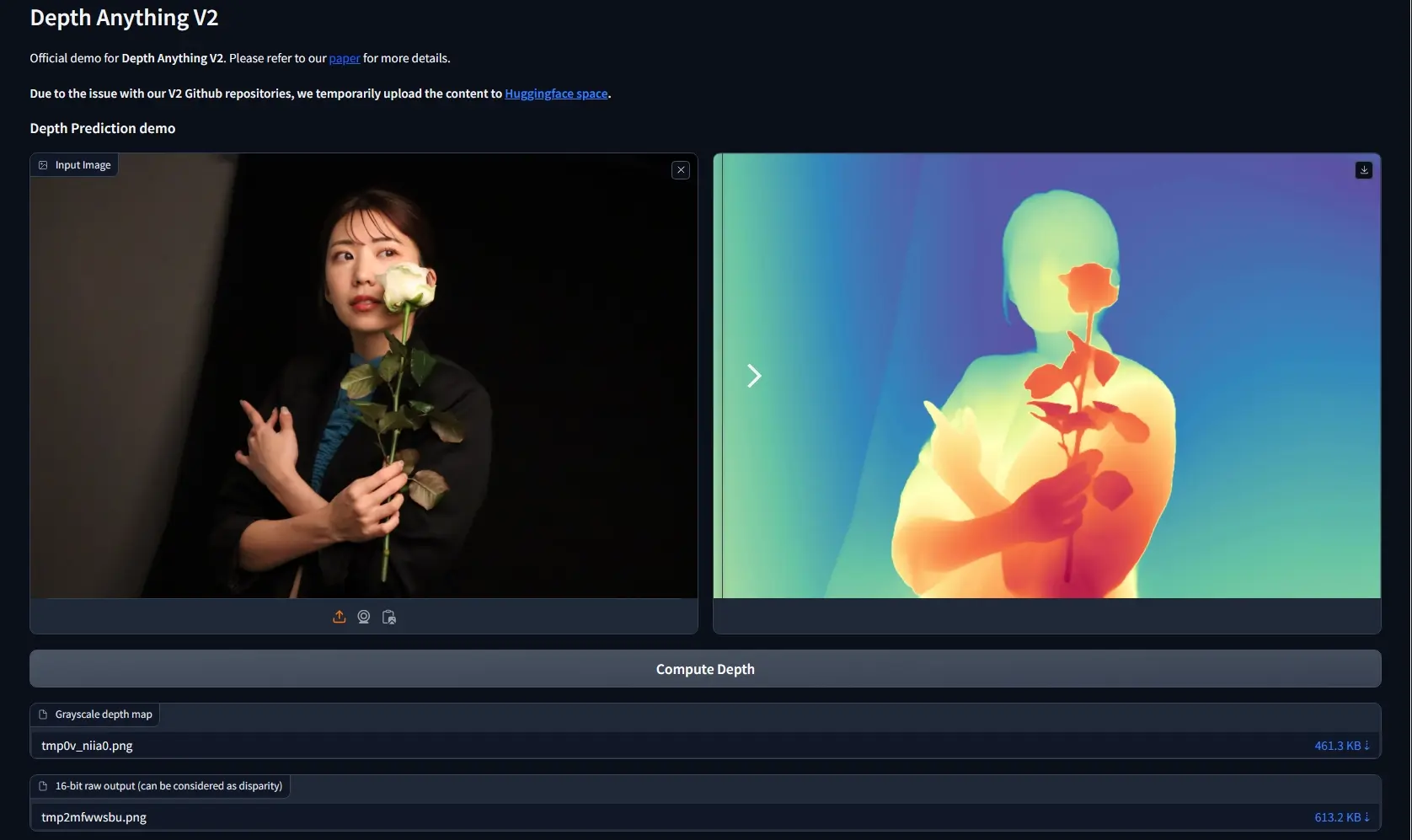
比如,在自动驾驶场景中,Depth Anything V2能够分析由车载摄像头拍摄的路面图像,预测行人、车辆和其他障碍物的距离,帮助汽车做出避让或减速的决策。在3D设计领域,设计师可以上传一张室内装饰的图片,Depth Anything V2能够预测出墙壁、家具等物体的深度信息,辅助设计师在虚拟空间中进行设计和布局。
主要功能:
- 深度预测:Depth Anything V2能够为单张图片生成深度图,预测图中各个物体的相对和绝对距离。
主要特点:
- 精细度和鲁棒性:与前一版本(V1)相比,V2版本在细节处理上更为精细,对复杂场景的预测更加稳健。
- 使用合成图像:该模型训练时不使用真实图像标签,而是全部替换为合成图像,以提高深度标签的精确度。
- 大规模伪标签真实图像:通过利用大规模未标记的真实图像和大型教师模型,V2版本在保持精确度的同时,增强了模型对真实世界场景的泛化能力。
工作原理:
- 合成图像训练:首先,使用合成图像训练一个基础的教师模型,这些图像的深度标签非常精确。
- 伪标签生成:然后,利用这个教师模型为大规模的真实图像生成伪深度标签。
- 学生模型训练:最后,训练多个规模不等的学生模型,这些模型只使用带有伪标签的真实图像进行训练。
具体应用场景:
- 自动驾驶:在自动驾驶汽车中,精确的深度信息对于理解周围环境和做出安全驾驶决策至关重要。
- 3D建模和设计:在3D建模中,深度估计可以帮助设计师从2D图片中重建3D场景或物体。
- 虚拟现实和增强现实:为虚拟或增强现实应用提供深度信息,以实现更真实的交互体验。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











