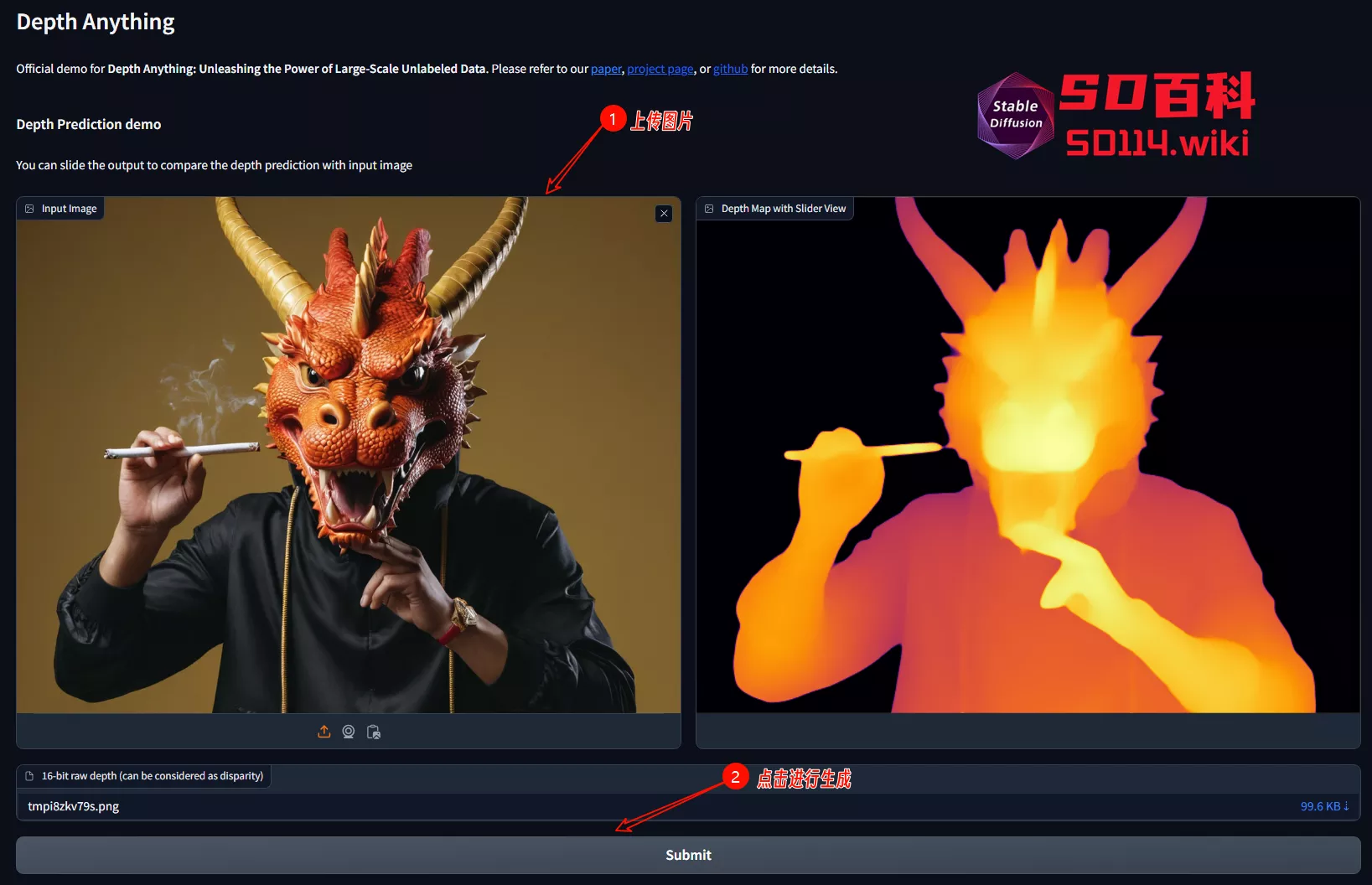
来自香港大学、TikTok、浙江实验室、浙江大学的研究人员推出了深度估算模型Depth Anything,它是一个用于单目深度估计(Monocular Depth Estimation, MDE)的实用解决方案。
- 项目主页:https://depth-anything.github.io
- GitHub:https://github.com/LiheYoung/Depth-Anything
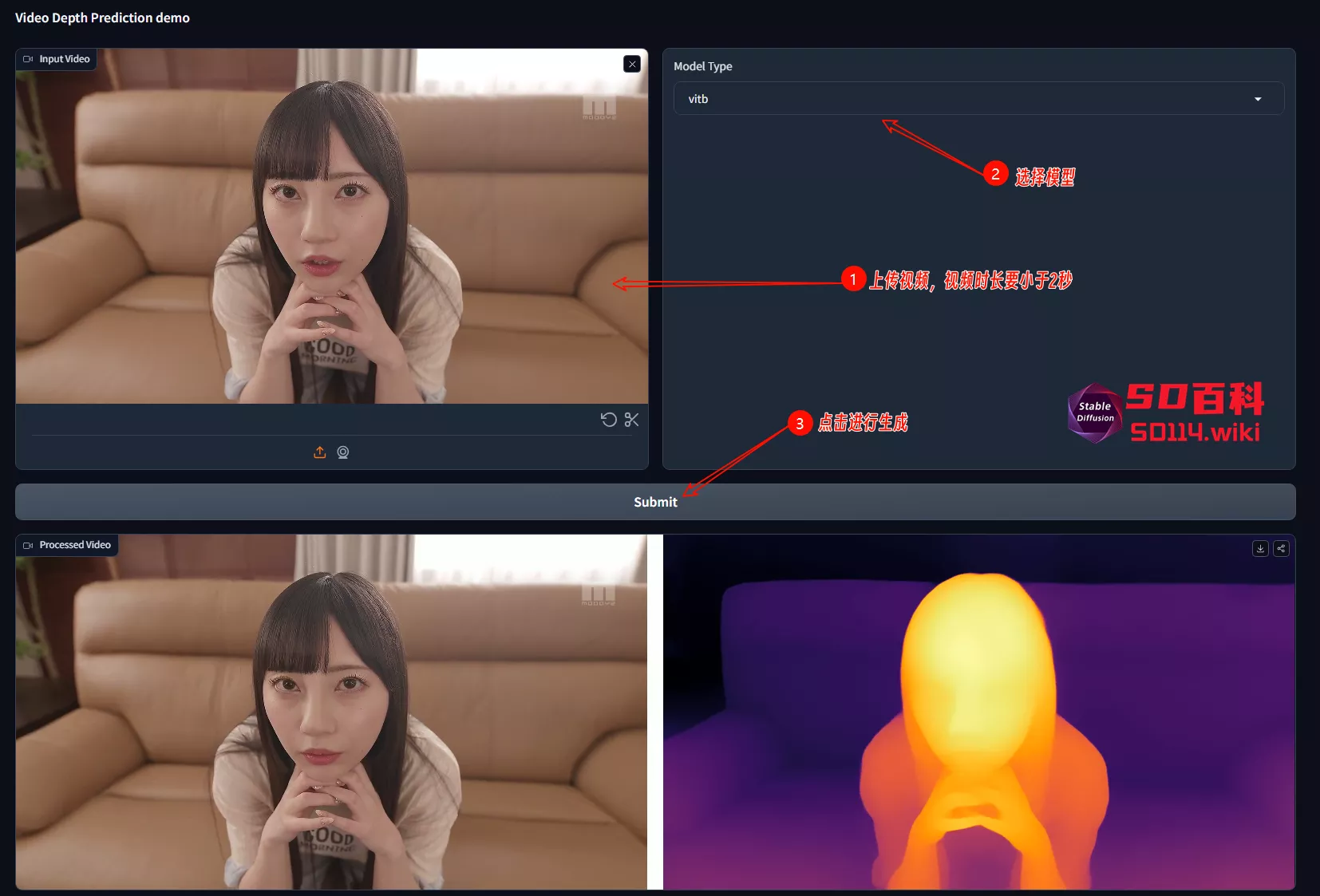
- 图片Demo:https://huggingface.co/spaces/LiheYoung/Depth-Anything
- 视频Demo:https://huggingface.co/spaces/JohanDL/Depth-Anything-Video
- 模型地址:https://huggingface.co/spaces/LiheYoung/Depth-Anything
这个模型的目标是在任何情况下都能对任何图像进行准确的深度估计。为了实现这一目标,研究者们通过设计一个数据引擎来收集和自动标注大规模的未标记数据(约6200万张),从而显著扩大了数据覆盖范围,减少了泛化误差。

他们还探索了两种简单但有效的策略来充分利用这些数据,包括通过数据增强工具创建更具挑战性的优化目标,以及开发辅助监督来使模型从预训练编码器中继承丰富的语义先验知识。
主要功能:
- 提供准确的单目深度估计,即使在没有深度标签的情况下也能对图像进行深度预测。
- 在多个公共数据集和随机捕获的照片中展示了出色的泛化能力。
主要特点:
- 利用大规模未标记数据进行训练,提高了模型的泛化能力和鲁棒性。
- 在学习未标记图像时,通过引入强扰动来挑战学生模型,迫使其学习更强大的视觉知识。
- 使用辅助特征对齐损失来保留预训练编码器的丰富语义先验知识。
工作原理:
- 首先,研究者们从六个公共数据集中收集了150万张标记图像来训练一个初始的深度估计模型。
- 然后,使用这个模型为6200万张未标记图像生成伪深度标签,这些图像来自八个大规模的公共数据集。
- 最后,在一个自训练的方式中,将标记集和伪标记集合并,训练一个学生模型。
应用场景:
- 在机器人技术、自动驾驶、虚拟现实等领域,Depth Anything可以用于估计场景的深度信息,帮助机器人导航或车辆理解周围环境。
- 在计算机视觉研究中,这个模型可以作为一个基础模型,用于开发更高级的视觉任务,如图像分割、3D重建等。
- 在内容创作和娱乐领域,Depth Anything可以帮助生成具有深度信息的图像和视频,用于增强现实(AR)和虚拟现实(VR)应用。
Depth Anything通过利用大规模未标记数据和先进的训练策略,展示了在单目深度估计任务上的突破性进展,尤其是在零样本(zero-shot)场景下的泛化能力。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











