阳明交通大学、东京大学和联发科的研究人员推出DiffIR2VR-Zero,它能够实现零样本(zero-shot)视频恢复。零样本意味着这种方法不需要针对特定任务进行训练,就能将低质量的视频转换成高质量的视频。这就像是一个万能的视频修复工具,无论视频是模糊的、有噪声的,还是分辨率太低,它都能帮助我们恢复出清晰、流畅的视频画面。
- 项目主页:https://jimmycv07.github.io/DiffIR2VR_web
- GitHub:https://github.com/jimmycv07/DiffIR2VR-Zero
- Demo:https://huggingface.co/spaces/Koi953215/DiffIR2VR
例如,我们有一段老旧的家庭录像,由于年代久远,录像的画质非常差,有很多噪点,分辨率也很低。使用DiffIR2VR-Zero技术,我们可以将这段录像转换成高清、流畅的视频,即使是在快速运动的场景下,人物的每一个细节都能清晰可见,没有模糊或闪烁的现象。这样,我们就能更好地保存和分享这些珍贵的记忆了。
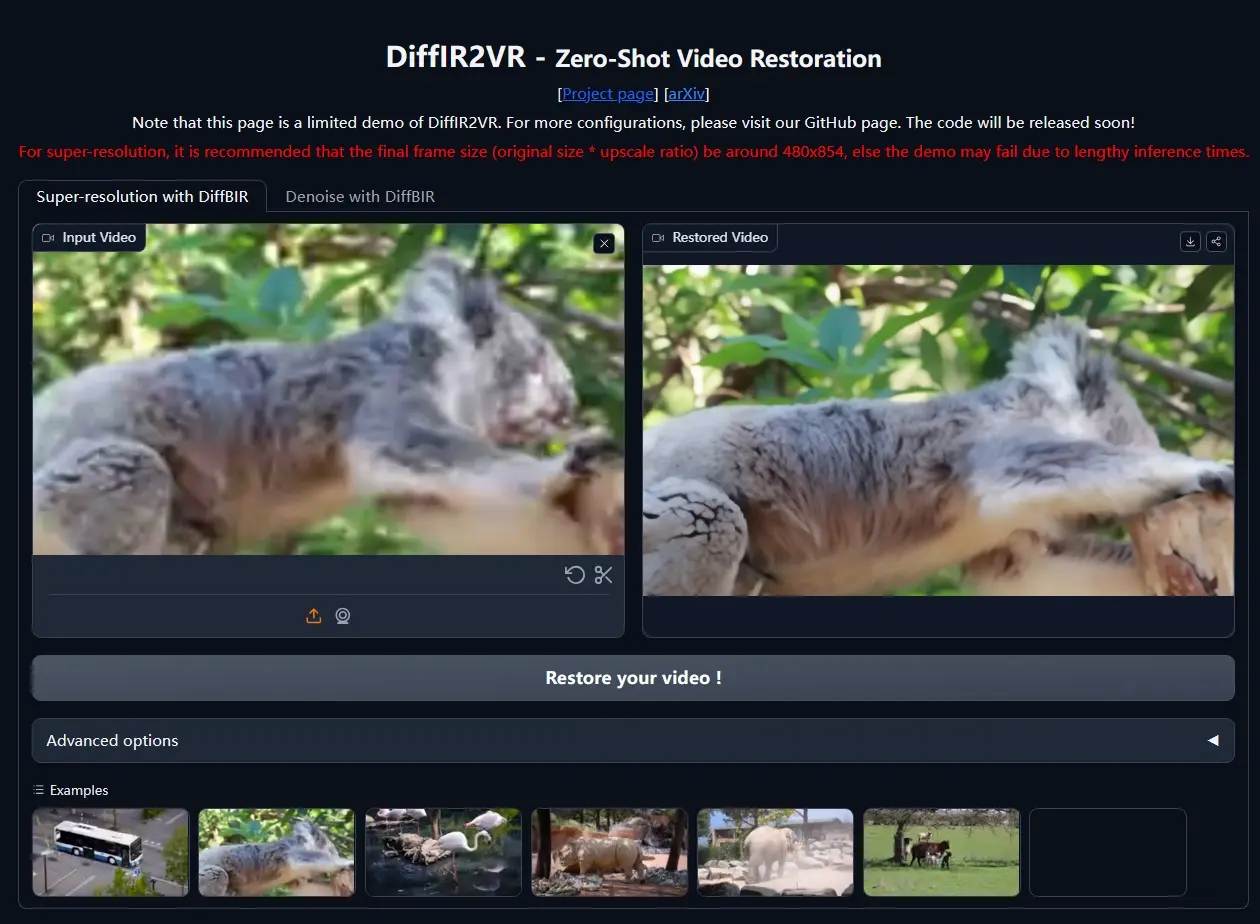
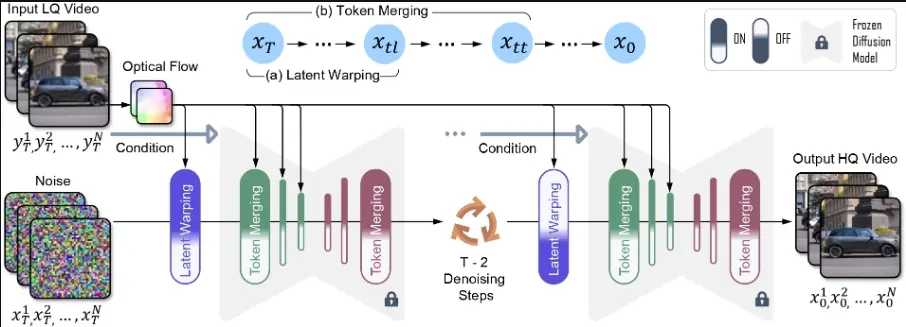
DiffIR2VR-Zero利用预先训练好的图像复原扩散模型来进行零样本视频复原,采用了一种层次化的关键帧与局部帧令牌合并策略,并融合了光学流与基于特征的最近邻匹配(隐含合并)的混合对应方法。实验表明,该方法不仅能实现零样本视频复原的顶尖效果,还在广泛的数据集及极端退化情况(例如8倍超分辨率和高噪声水平的视频降噪)下,展现出远超特训模型的泛化能力。通过在多类复杂数据集上的量化评估与直观比较,验证了这一结论。尤为重要的是,该技术能够与任意2D复原扩散模型无缝对接,为视频提升任务提供了一个强大且适应性广的解决方案,无需深度重新训练。
主要功能和特点:
- 零样本学习:无需针对特定类型的视频退化进行训练或微调。
- 保持时间一致性:在视频的每一帧之间保持视觉效果的连贯性,避免画面闪烁。
- 高质量视频输出:即使在极端的退化条件下(如8倍超分辨率和高标准偏差的视频去噪),也能生成高质量的视频。
- 通用性:适用于任何2D图像恢复扩散模型,提供一种多功能且强大的视频增强工具。
工作原理:
DiffIR2VR-Zero使用了一个分层的令牌合并策略和混合对应机制。具体来说,它包括以下几个关键步骤:
- 关键帧和局部帧的分层令牌合并:通过在关键帧之间传递潜在表示(latents),来保持视频帧之间的全局和局部一致性。
- 混合流引导的空间感知令牌合并:结合光流和基于特征的最近邻匹配,来提高帧间特征的对应精度,从而增强视频的整体一致性。
- 无需训练的模块:这些模块可以直接应用于任何预训练的图像扩散模型,无需额外的训练或微调。
具体应用场景:
- 视频质量提升:将老旧或损坏的视频资料转换成高质量的视频,适用于视频编辑和存档。
- 视频监控分析:提高监控视频的清晰度,帮助更好地进行安全监控和事件分析。
- 视频内容创作:为视频创作者提供工具,让他们能够轻松修复和增强视频内容,无需专业的视频编辑技能。
- 多媒体展示:在博物馆、展览等场合,将历史影像资料以高质量形式展示给观众。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...