
腾讯和上海交通大学的研究人员推出高质量人类动作视频生成框架MimicMotion,依据任意运动指令生成高质感、任意长度的视频内容。简单来说,MimicMotion是一个可以制作出逼真人类动作视频的智能系统,它能够根据特定的动作指导生成任意长度的视频。这就像是一个高级版的“换脸”技术,但不仅仅局限于换脸,还能生成整个人的动作和表情。
- 项目主页:https://tencent.github.io/MimicMotion
- GitHub:https://github.com/tencent/MimicMotion
- ComfyUI插件:https://github.com/AIFSH/ComfyUI-MimicMotion
- Colab地址:https://github.com/camenduru/MimicMotion-jupyter
例如,你是一名舞蹈教练,想要在网上发布教学视频,但缺少拍摄和编辑的资源,你可以使用MimicMotion。你只需要提供一段舞蹈动作的描述或图片,以及你的图片,MimicMotion就能生成一个视频,展示你在跳舞。这个视频可以是任意长度,动作流畅自然,就像你亲自跳的一样。这样,你就能用这种低成本的方式创作出专业的舞蹈教学内容。
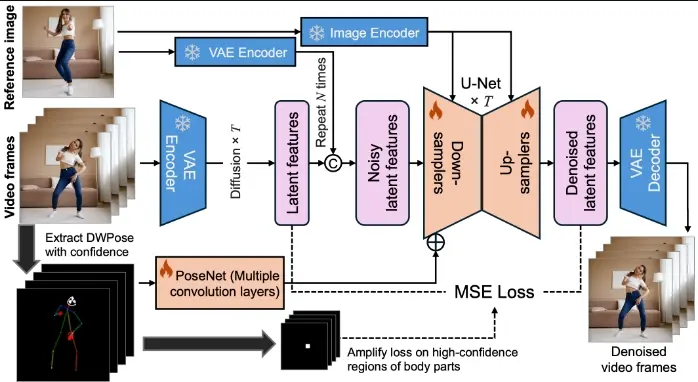
MimicMotion与既往方案相比较,本框架具备多项优势:其一,融入了信任度感知的姿态引导机制,不仅确保了视频的时间连贯性,还借助大规模训练资料有效提升了模型的稳健性。其二,通过利用姿态信任度进行局部损失增强,极大缓解了图像失真现象。其三,为了创造既长又流畅的视频,研究团队创新性地引入了递进式潜在融合策略,这一策略使得在合理资源占用下生成任意时长视频成为可能。

主要功能和特点:
- 可控性:用户可以通过提供参考图片和动作序列来控制视频的输出。
- 高质量和细节丰富:生成的视频不仅清晰度高,而且细节丰富,包括人物的手部动作等。
- 时间平滑性:视频帧与帧之间的过渡自然流畅,没有突兀的跳跃或闪烁。
- 任意长度视频生成:与以往技术相比,MimicMotion能够生成更长的视频,同时保持高质量。
工作原理:
MimicMotion的工作原理可以分为几个关键步骤:
- 信心感知的姿态引导:系统会根据姿态估计模型提供的信心分数来调整姿态引导的强度,这样即使在姿态估计不准确的情况下也能保持视频质量。
- 区域损失放大:对于信心度高的身体部位,如手部,系统会在训练过程中增加这些区域的损失权重,以减少图像失真。
- 渐进式潜在融合:为了生成长视频,系统会将视频序列分割成多个段,并在去噪过程中融合重叠帧的潜在特征,从而实现平滑的视频过渡。
具体应用场景:
- 虚拟现实和游戏:在虚拟现实或游戏中生成逼真的人类角色动作。
- 电影和视频制作:用于制作电影或视频内容,特别是当需要复杂动作或危险动作时。
- 动画制作:动画师可以使用这项技术来生成动画角色的动作,提高工作效率。
- 社交媒体内容创作:用户可以创建带有自己动作的虚拟形象视频,用于社交媒体分享。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











