
卡内基梅隆大学、Adobe 研究和加州大学伯克利分校的研究人员发布论文,论文的主题是关于文本到图像模型的数据归因(Data Attribution for Text-to-Image Models),即识别在生成新图像过程中最具影响力的训练图像。这项研究的目标是理解在训练大规模文本到图像生成模型时,哪些特定的训练数据对生成特定输出图像起到了关键作用。
- 项目主页:https://peterwang512.github.io/AttributeByUnlearning
- GitHub:https://github.com/peterwang512/AttributeByUnlearning
例如,我们有一个文本到图像的生成模型,用户输入了一段描述,比如“一只在雪地中穿行的蓝色外套的滑雪者”,模型生成了一张符合描述的图像。数据归因的目的就是要找出训练集中哪些图像对这个生成结果影响最大。
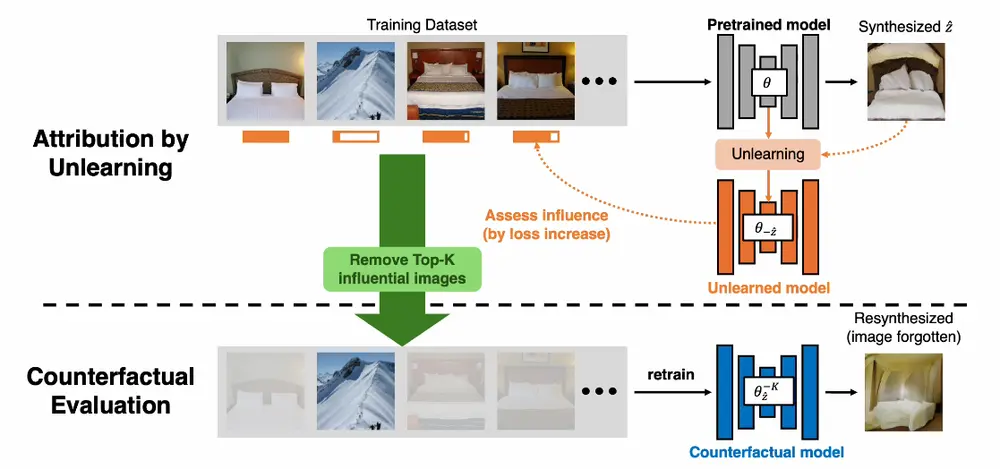
主要功能
- 识别关键训练图像:确定哪些训练图像对生成特定输出图像贡献最大。
- 模拟“反学习”过程:通过增加目标图像的训练损失来模拟从模型中“删除”这些图像的效果,同时尽量保留其他无关概念的记忆。
主要特点
- 高效性:提出了一种新方法,避免了直接从头开始重新训练模型的高计算成本。
- 有效性:通过“反学习”合成图像,而不是单独对每个训练图像进行“反学习”,减少了所需的优化次数。
- 对抗性遗忘:使用Fisher信息来正则化梯度方向,减少遗忘其他无关概念的风险。
- 针对性权重优化:只更新模型中的关键权重,特别是交叉注意力层的键和值映射。
工作原理
- 模拟“反学习”:通过优化一个目标函数来增加合成图像的训练损失,同时使用Fisher信息来保留预训练信息,避免灾难性遗忘。
- 评估影响:通过比较“反学习”前后训练图像的损失变化来评估每个训练图像的影响。
- 关键权重优化:只更新交叉注意力层中的键和值映射,以提高归因性能。
具体应用场景
- 版权和授权:在创意产业中,了解哪些训练图像对生成的图像贡献最大可以帮助确定版权归属和授权问题。
- 透明度和可解释性:为用户提供模型行为的透明度,增加对机器学习模型的信任。
- 补偿模型贡献者:为训练数据的提供者建立补偿模型,根据其数据对模型输出的贡献大小进行奖励。
- 模型调试和改进:通过识别影响输出的关键数据,可以帮助开发者理解模型的弱点并进行改进。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











