华中科技大学和vivo AI 实验室的研究人员推出新型图像分割模型EVF-SAM,EVF-SAM的核心特点是它能够理解文本提示,并根据这些提示对图像中的对象进行精确分割。这项技术对于那些需要根据用户描述来识别和分割图像中特定对象的应用场景非常有用。例如,你是一名摄影师,你想要从一堆照片中快速选取并编辑出所有包含“蓝色衬衫”的照片。使用EVF-SAM,你只需输入文本提示“蓝色衬衫”,模型就能自动识别并分割出所有穿着蓝色衬衫的人物,从而大大加快了照片筛选和编辑的过程。
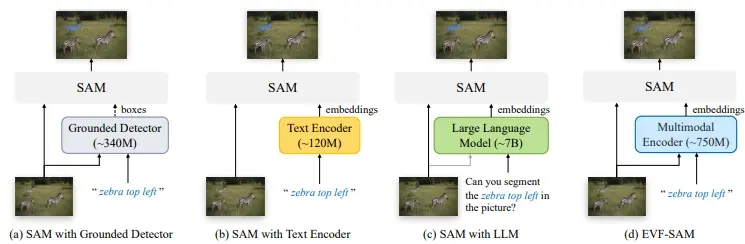
EVF-SAM是一种简单而有效的指代分割方法,它利用多模态提示(即图像和文本),结合预训练的视觉-语言模型来生成指代提示,并借助SAM模型完成分割任务。令人惊讶的是,研究人员观察到:(1) 多模态提示的使用,以及(2) 采用早期融合的视觉-语言模型(例如BEIT-3),对于引导SAM实现精确的指代分割极为有利。实验结果显示,基于BEIT-3的提出的EVF-SAM在RefCOCO/+/g数据集上的指代表达分割任务上达到了最先进的性能,彰显了利用早期视觉-语言融合引导SAM的优越性。此外,与基于大型多模态模型的先前SAM方法相比,所提出的EVF-SAM虽然仅有13.2亿参数,却在减少近82%参数量的同时,实现了显著更高的性能表现。
主要功能:
- 文本提示分割:EVF-SAM可以根据用户给出的文本描述,如“照片中的蓝色衬衫”,来识别并分割出图像中的特定对象。
主要特点:
- 多模态提示:EVF-SAM利用图像和文本的多模态提示来生成分割提示,这比仅使用文本或图像的单一模态提示更有效。
- 早期视觉-语言融合:模型采用了早期视觉-语言融合技术,这有助于更好地理解文本和图像之间的关系,从而提高分割的准确性。
- 参数效率:尽管EVF-SAM性能出色,但它的参数数量比之前基于大型多模态模型的SAM方法减少了近82%,这使得模型更加轻量化。
工作原理:
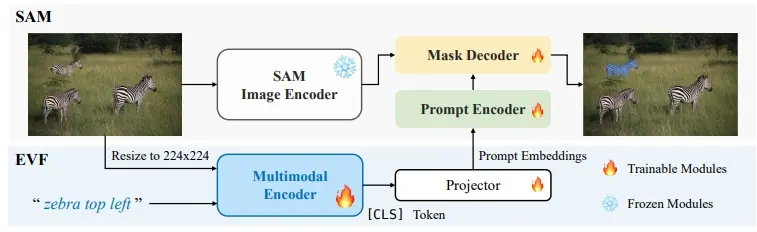
- 多模态编码器:EVF-SAM使用一个预训练的多模态编码器(如BEIT-3)来处理输入的文本和图像,生成融合的多模态嵌入。
- 投影器:通过一个简单的多层感知机(MLP)投影器,将多模态编码器的输出[CLS]标记投影为分割模型的提示嵌入。
- Segment Anything Model (SAM):将投影得到的提示嵌入输入到SAM模型中,SAM模型根据这些嵌入生成最终的分割结果。
具体应用场景:
- 图像编辑:用户可以给出文本指令,EVF-SAM能够自动选择和分割图像中的特定对象,方便进行编辑或修改。
- 内容创作:在创作过程中,根据文本描述快速生成或修改图像内容,提高创作效率。
- 视觉搜索:通过文本描述来搜索图像库中的对象,EVF-SAM可以快速定位和分割出相关图像。
- 增强现实(AR):在AR应用中,根据用户的文本指令,实时分割和展示现实世界中的特定对象。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











