
来自Meta的研究人员推出了AI视频生成模型Animated Stickers,它可以让普通表情包图片“动”起来。这项技术的核心是利用先进的文本到图像(Text-to-Image)模型,通过添加时间层来模拟运动,从而生成与文本描述相符的动画贴纸。
具体来说,这项技术能够根据给定的文字描述和一张静态的表情包图片,生成一个有趣的动画视频。想象一下,你有一张普通的狗狗表情包,通过这项技术,你可以让它在视频中摇头摆尾,仿佛真的活了起来。

主要功能:
- 动画生成:根据用户提供的文字描述和静态贴纸图片,自动生成一个动态的动画视频。
- 高度自定义:用户可以根据自己的喜好和创意,为贴纸图片添加各种有趣的动作和表情。
主要特点:
- 使用了两阶段的微调(finetuning)流程,首先使用弱领域数据(weakly in-domain data),然后采用人类参与循环(Human-in-the-loop, HITL)策略,称为“教师集合”(ensemble-of-teachers),将多个“教师”模型的最佳特性融合到一个较小的学生模型中。
- 通过推理优化,如降低浮点精度、减少模型评估次数、使用TorchScript序列化模型等,提高了模型的推理速度。
- 在训练过程中,采用了中间帧条件(middle frame conditioning)和运动桶(motion bucketing)等技术来提高动画质量和一致性。
工作原理:
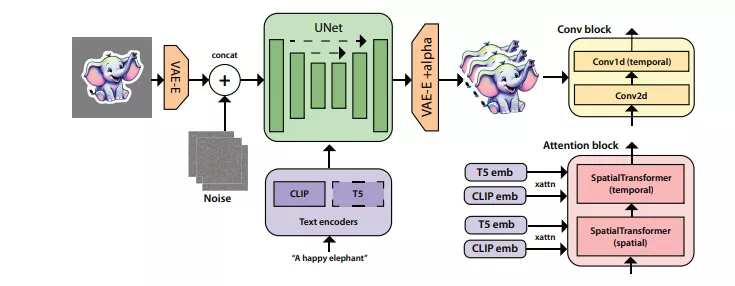
- 模型基于Emu文本到图像模型构建,通过在ResNet块中插入1D卷积和时间注意力层来模拟运动。
- 使用变分自编码器(VAE)和UNet网络结构,结合文本编码器(如CLIP和Flan-T5-XL)来处理文本提示。
- 在训练过程中,首先在大量自然视频数据集上预训练模型,然后通过领域特定的数据集进行微调,最后使用HITL策略进一步优化模型。
应用场景:
- 在社交媒体平台上,用户可以创建个性化的动画贴纸,用于表达情感或分享有趣的内容。
- 在游戏和应用程序中,可以生成与玩家动作或游戏事件相关的动态贴纸。
- 在广告和营销领域,可以快速生成与品牌或产品相关的动态视觉内容。
这项技术通过结合文本描述和静态图像,生成生动的动画效果,为用户提供了一种新颖的创意表达方式。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











