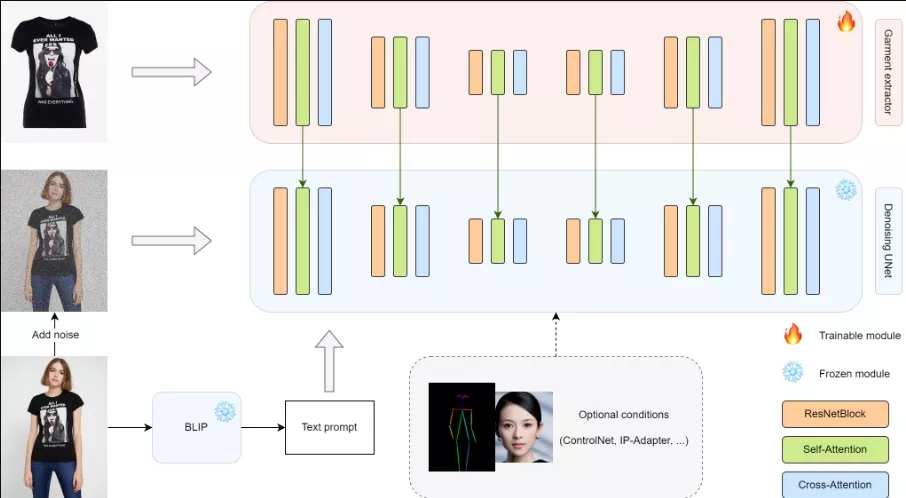

小i研究院发布了OOTDiffusion的分支版本Magic Clothing,它能够根据特定的服装和文本提示来生成穿着这些服装的定制化角色图像。这项技术的核心在于高度的图像可控性,即在生成的图像中保留服装的细节,同时忠实于文本提示的内容。开发团队设计了一个服装提取器来捕捉服装的详细特征,并通过自注意力融合技术将这些特征融入预训练的模型中,确保目标角色身上的服装细节与原始设计保持一致。此外,还采用了联合无分类器引导策略,以在服装特征和文本提示之间取得平衡,进而优化生成结果的控制效果。
- GitHub:https://github.com/ShineChen1024/MagicClothing
- 模型地址:https://huggingface.co/ShineChen1024/MagicClothing
值得一提的是,开发团队提出的服装提取器是一个灵活且易于集成的模块,可以适应各种微调后的模型。同时,它还可以与其他扩展功能(如ControlNet和IP-Adapter)相结合,进一步提升生成角色的多样性和可控性。为了评估生成图像与原始服装的一致性,开发团队还设计了一种名为Matched-Points-LPIPS(MP-LPIPS)的稳健度量指标。
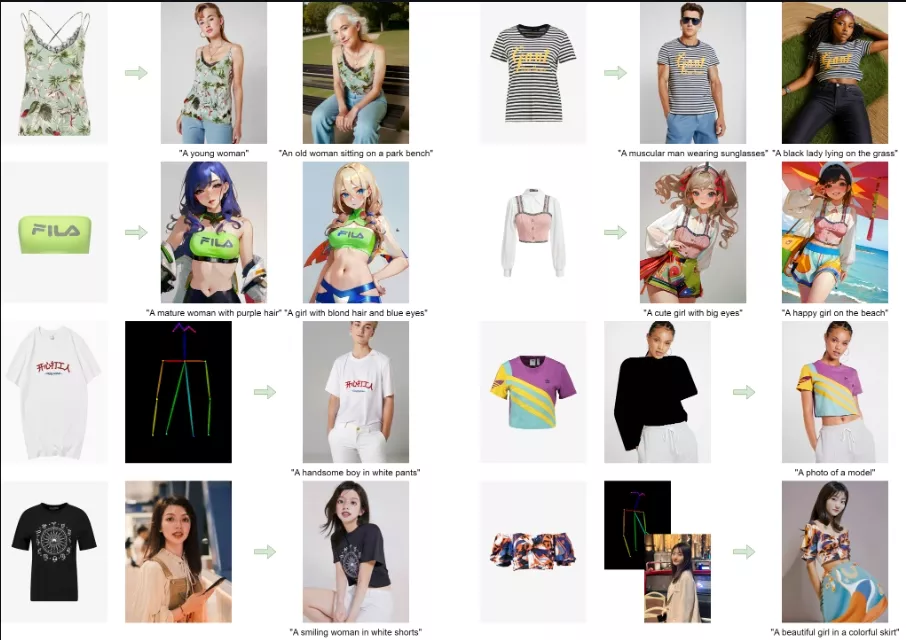
例如,你是一名服装设计师,想要快速预览你的设计在不同类型人物上的效果。你可以选择一件服装的图片,输入文本提示如“一个穿着这件礼服的亚洲女性”,然后“Magic Clothing”系统会生成一系列穿着该礼服的亚洲女性图像,帮助你评估服装设计的适应性和吸引力。
主要功能:
- 服装驱动的图像合成:用户可以指定一个目标服装,系统将生成一个穿着该服装的角色图像。
- 文本提示响应:系统可以根据用户输入的文本提示(如“一个穿着晚礼服的年轻女子”)来定制生成的图像风格和内容。
主要特点:
- 细节保留:特别设计了一个服装提取器来捕捉服装的详细特征,并确保这些细节在生成的角色图像中得以保留。
- 自注意力融合:通过自注意力机制将服装特征融合到预训练的潜在扩散模型(LDM)中,增强了图像的细节表现力。
- 插件模块:提出的服装提取器是一个插件模块,可以与多种微调的LDM或其他扩展(如ControlNet和IP-Adapter)结合使用,以增加生成角色的多样性和可控性。
- 评价指标:设计了一种新的健壮评价指标Matched-Points-LPIPS(MP-LPIPS),用于评估目标图像与源服装的一致性。
工作原理:
- 服装特征提取:使用UNet架构的服装提取器来提取服装的详细特征。
- 自注意力融合:将提取的服装特征通过自注意力机制融合到去噪UNet中,确保服装细节在生成的图像中得以保留。
- 联合分类器自由引导:在训练过程中,通过随机丢弃服装特征和文本提示,实现对服装特征和文本提示控制的平衡。
- 插件模块训练:服装提取器作为一个插件模块,可以与其他微调的LDMs结合,以实现更多的条件控制。
具体应用场景:
- 电子商务:顾客可以上传自己想要的服装图片,系统生成模特穿着该服装的图片,帮助顾客更直观地了解服装效果。
- 虚拟试衣:在虚拟试衣间中,用户可以生成自己穿着不同服装的图像,而无需实际试穿。
- 角色设计:游戏或动画制作人员可以根据文本描述快速生成角色的服装设计草图。
- 个性化内容创作:艺术家和设计师可以使用这个系统来根据他们的创意文本提示生成独特的角色图像。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











