
关键要点摘要:
- Stable Cascade模型发布: 今天,Stability AI推出了基于Würstchen架构的文生图模型Stable Cascade,并仅允许在非商业许可下使用,限定于非商业用途。
- 易于训练与微调属性: Stable Cascade得益于其独特的三阶段设计,在消费级硬件上展现出极高的易训练性和可微调性,大大降低了对专业级硬件的要求。
- 配套代码与资源分享: Stability AI在GitHub上提供了Stable Cascade的代码和资源,包括模型、推理脚本和微调脚本,,还包括针对ControlNet和LoRA的专门训练脚本,方便用户进行个性化调整和实验。
今日,Stability AI正式推出Stable Cascade模型的科研预览版。这款创新的文生图模型引入了一种引人注目的三阶段处理策略,在质量、灵活性、微调性能及效率方面均设立了新的标杆,尤其专注于进一步消除硬件门槛。
- 官方介绍:https://stability.ai/news/introducing-stable-cascade
- GitHub:https://github.com/Stability-AI/StableCascade
- 模型地址:https://huggingface.co/stabilityai/stable-cascade
- Demo:https://huggingface.co/spaces/multimodalart/stable-cascade

技术详情
Stable Cascade与现有的Stable Diffusion系列模型有所不同。Stable Cascade的构建基于一个流水线,该流水线由三个独立模型——Stages A、B和C组成。这种架构支持图像的层级压缩,在利用高度压缩的潜在空间的同时,能够实现卓越的输出效果。接下来,我们将逐一分析每个阶段以了解它们是如何协同工作的:
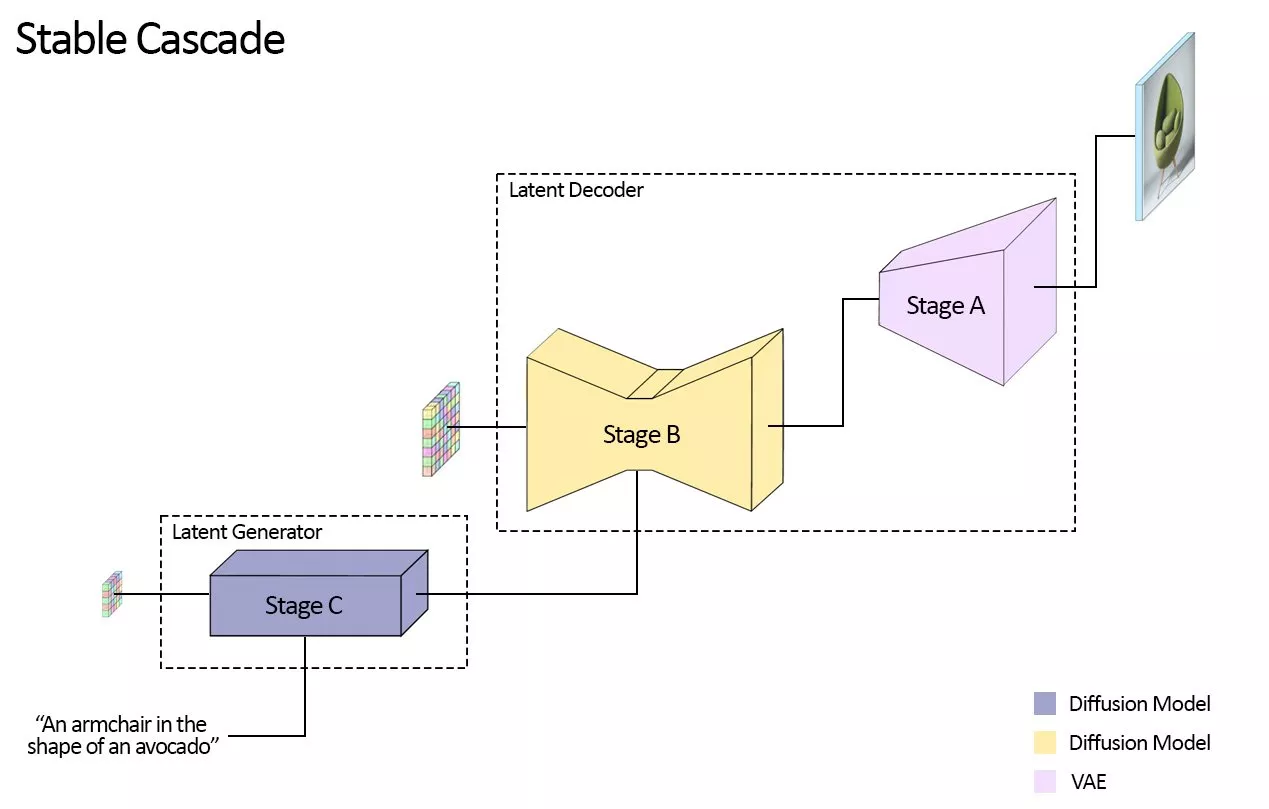
潜码生成阶段,即Stage C,将用户输入转化为紧凑的24x24维度潜码,并将其传递给潜码解码阶段(Stages A和B)。这一阶段类似Stable Diffusion中的VAE所承担的图像压缩任务,但实现了更高的压缩率。
通过将文本条件生成(Stage C)与高分辨率像素空间解码(Stages A和B)相分离,我们可以在Stage C上独立完成额外的训练或微调操作,包括ControlNets和LoRAs等技术。与训练同等规模的Stable Diffusion模型相比,这种方法带来了16倍的成本降低(原论文中有展示)。Stages A和B也可以选择性地进行微调以增强控制能力,但这相当于对Stable Diffusion模型中VAE部分进行微调。对于大多数应用场景来说,单独训练Stage C并在原始状态下使用Stages A和B就已足够,这样做提供的额外收益较小。
Stages C和B将分别发布两个不同参数量的模型版本:Stages C有1B和3.6B参数版本,而Stages B则提供700M和1.5B参数版本。推荐使用3.6B参数版本的Stages C,因为该模型能输出最高质量的结果。不过,如果关注最低硬件要求,可以选择1B参数版本。对于Stages B,两个版本都能取得出色结果,其中1.5B参数版本尤其擅长重建精细细节。得益于Stable Cascade模块化的设计方式,在推理过程中预计VRAM需求可保持在约20GB左右,若采用较小参数量的变体,还能进一步降低内存需求(如前所述,这也可能会导致最终输出质量有所下降)。
如果上面的太复杂不好理解,可以看下面的例子:
假设我们有一个任务:将文本描述“一只在海滩上漫步的可爱小狗”转换成一张图像。
文本条件生成(Stage C):
- 首先,我们将文本描述输入到Stage C中。Stage C是一个潜码生成器,它负责将文本描述转化为一个紧凑的24x24潜码。这个潜码可以看作是文本描述的一种数值化表示,它包含了生成图像所需的所有关键信息。
- 例如,这个潜码可能包含了关于小狗的品种、颜色、姿态,以及海滩的环境特征等信息。
潜码解码(Stages A和B):
- 接下来,这个潜码被传递给Stages A和B进行解码。Stages A和B共同负责将潜码还原成一张高分辨率的图像。
- Stage A可能首先生成一个低分辨率的图像框架,包括海滩的基本背景和小狗的大致位置。然后,Stage B对这个框架进行细化,添加更多的细节,比如小狗的毛发、眼睛、耳朵等特征,以及海滩上的沙子、海浪等元素。
- 这个过程中,Stages A和B可能会参考预训练的模型和数据集,以确保生成的图像既符合文本描述,又具有真实感。
额外的训练或微调(可选):
- 在某些情况下,我们可能希望对生成的图像进行进一步的优化或调整。这时,我们可以对Stages C、A或B进行额外的训练或微调。
- 例如,如果我们发现生成的小狗图像在某些方面(比如颜色、姿态)与文本描述不符,我们可以针对这些问题对Stage C进行微调,使其更加准确地捕捉文本中的关键信息。
- 同样,如果我们认为生成的图像在细节方面还有提升的空间,我们可以对Stage B进行额外的训练,以提高其生成细节的能力。
最终,经过Stages C、A和B的协同工作,我们可以得到一张符合文本描述、且具有高度真实感的图像:“一只在海滩上漫步的可爱小狗”。这就是Stable Cascade模型的工作过程。
比较
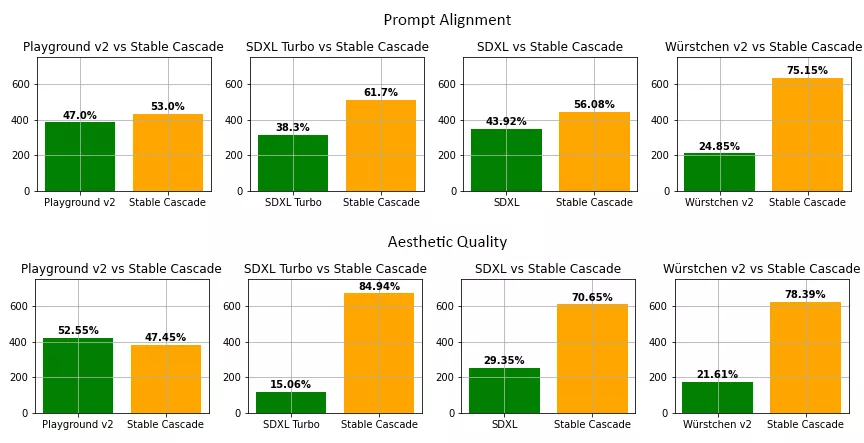
在我们的评估过程中,我们发现Stable Cascade在几乎所有模型对比中,在提示词对齐性和美学质量上都表现最优。以下是使用部分特定提示词和美学相关提示词进行的人工评价结果:
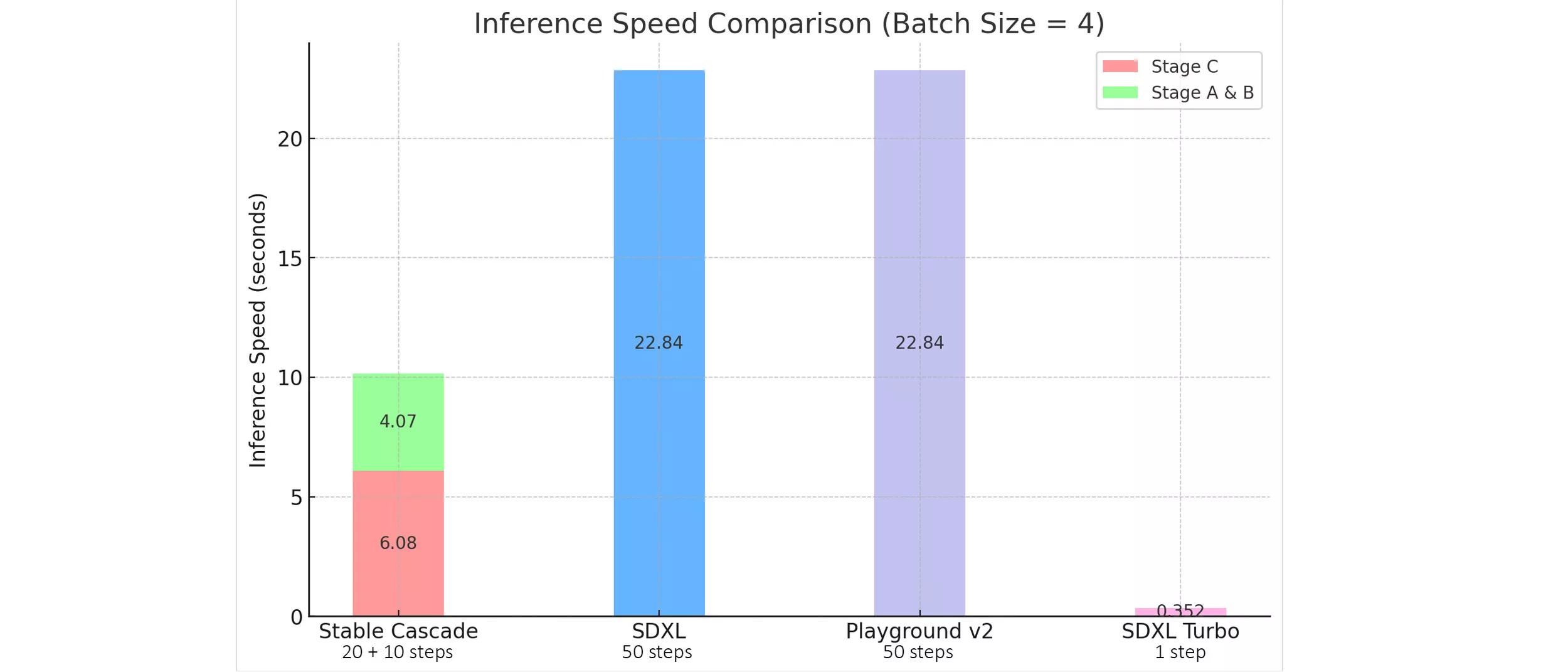
Stable Cascade 的效率优势在很大程度上是通过其独特的架构设计以及更高的压缩潜空间来体现的。尽管 Stable Cascade 中最大的模型相较于 Stable Diffusion XL 多出了14亿个参数,但在实际推理速度上却表现出更快的性能。下图直观地展示了这一特性:
附加功能
除了标准的文生图,Stable Cascade还能实现图像变种生成和图生图。
图像变种生成是通过使用CLIP从给定图像中提取图像嵌入,并将这些嵌入信息返回至模型进行处理。下面展示了一些示例输出,其中左侧的图像为原始图像,而右侧紧邻的四个图像即为基于该原始图像生成的不同变体。

图生图则是简单地向某一给定图像添加噪声,并以此作为生成过程的起点。下面是一个对左侧图像添加噪声并从那里进行生成的示例。

训练、微调、ControlNet和LoRA代码
随着Stable Cascade的发布,Stability AI发布了用于训练、微调、ControlNet和LoRA的全部代码,以进一步降低实验该架构技术门槛。以下是Stability AI将随模型一同发布的部分ControlNet功能:
- Inpainting / Outpainting:输入一幅图像及其配套的遮罩,并配合文本提示。模型将根据提供的文本提示填充图像中被遮罩的部分。

- Canny Edge:通过遵循现有输入图像的边缘来生成新的图像。经测试发现,该功能还可对草图进行扩展。

- 2x Super Resolution:将图像放大至其原始尺寸的两倍(例如,将1024 x 1024像素的图像转换为2048x2048像素输出),并且也可以应用于由Stage C生成的潜在特征向量上。

这些功能的具体信息可以在Stability GitHub页面上找到,包括训练和推理代码。尽管目前此模型暂不适用于商业目的,但如果您有兴趣探索使用Stability AI其他图像模型进行商业用途,请访问Stability AI会员页面了解关于自托管商业使用的详情,或访问Stability AI的开发者平台以接入Stability AI的API。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











