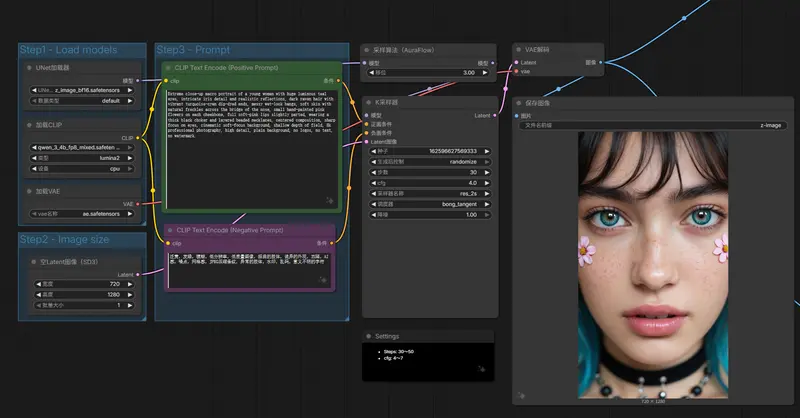
Z-Image 已获ComfyUI 原生支持:非蒸馏基础版,灵活可微调,直出体验一般ComfyUI 官方宣布,Z-Image(阿里通义 MAX 项目组发布的图像生成基础模型)现已获得 原生支持,用户可通过模板库直接调用。 Hugging Face:https://huggingfac...工作流# Z-Image# 文生图2个月前01030
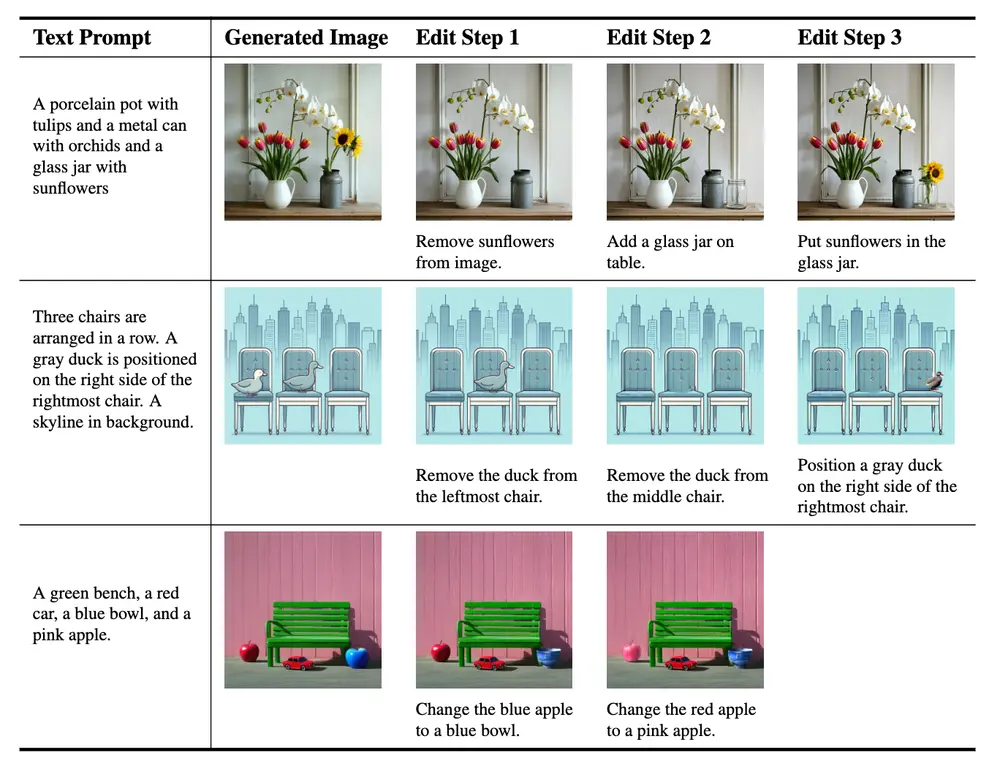
用于组合式文生图新框架GraPE:将复杂的多步生成任务分解为三个独立的步骤文本到图像(T2I)生成任务的目标是从文本提示生成逼真的图像。尽管扩散模型在这一领域取得了显著进展,但现有方法在处理复杂的多步推理和组合性提示时仍面临挑战。特别是,当文本提示包含多个对象及其属性之间的...新技术# GraPE# 文生图1年前03340
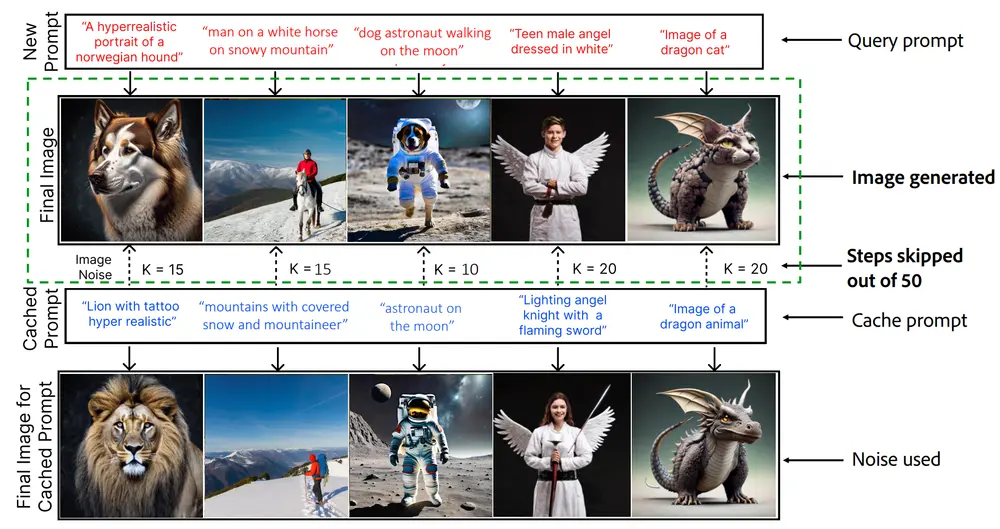
新型文本到图像生成系统NIRVANA:利用近似缓存技术,高效地服务基于扩散模型的文本到图像生成任务Adobe和伊利诺伊大学厄巴纳-香槟分校的研究人员介绍了一种名为NIRVANA的新型文本到图像生成系统,它利用了一种称为近似缓存(Approximate Caching)的技术,旨在高效地服务基于扩散...新技术# NIRVANA# 文生图1年前03790
新型文本到图像生成方法FRAP:基于自适应调整每个词汇的提示权重来改善生成图像与提示之间的一致性和真实性阿尔伯塔大学电子与计算机工程系、华为技术加拿大公司和华为麒麟解决方案的研究人员推出新型文本到图像生成方法FRAP,旨在提高由文本提示生成图像的真实性和忠实度,确保生成的图像与文本描述的内容精确匹配。F...新技术# FRAP# 文生图2年前04770
建立在多模态大语言模型基础上的统一文本到图像生成和检索框架TIGeR来自新加坡国立大学 NExT++ 实验室、南洋理工大学、香港理工大学和哈尔滨工业大学(深圳)的研究人员推出一个统一的文本到图像生成和检索框架TIGeR,这个框架建立在多模态大语言模型(MLLMs)的基...新技术# TIGeR# 文生图2年前07480
通用反馈学习架构ID-Aligner:用于提升文本到图像生成任务中的身份保持性能来自中山大学和字节跳动的研究人员推出通用反馈学习架构ID-Aligner,它用于提升文本到图像生成(Text-to-Image Generation)任务中的身份保持(Identity-Preserv...新技术# ID-Aligner# 人物特征# 文生图2年前08740
LaVi-Bridge:将不同的语言模型和生成视觉模型结合起来,用于文生图来自香港大学、香港中文大学、香港科技大学的研究团队推出LaVi-Bridge,它能够将不同的语言模型和生成视觉模型结合起来,用于文本到图像的生成任务。通过利用LoRA和适配器技术,LaVi-Bridg...新技术# LaVi-Bridge# 文生图2年前08800
无需训练的组合式文本到图像生成方法CompAgent来自清华大学、华为诺亚方舟实验室、香港大学的研究人员提出了一种无需训练的组合式文本到图像生成方法CompAgent,该方法利用大语言模型(LLM)智能体进行复杂文本提示的分析与规划,将文本分解为单个对...新技术# CompAgent# 华为诺亚方舟# 文生图2年前06940
单样本文生图模型的微调方法:解决泛化性和真实性问题来自腾讯的研究人员提出了一种面向对象的单样本文生图模型的微调方法Object-Driven One-Shot Fine-tuning of Text-to-Image Diffusion with P...新技术# Lora# 微调# 文生图2年前07160