
来自中山大学和字节跳动的研究人员推出通用反馈学习架构ID-Aligner,它用于提升文本到图像生成(Text-to-Image Generation)任务中的身份保持(Identity-Preserving)性能。简单来说,这个框架可以帮助生成与特定人物特征(如外貌、服饰等)保持一致的图像,即使在不同的文本提示下也能保持人物的一致性。
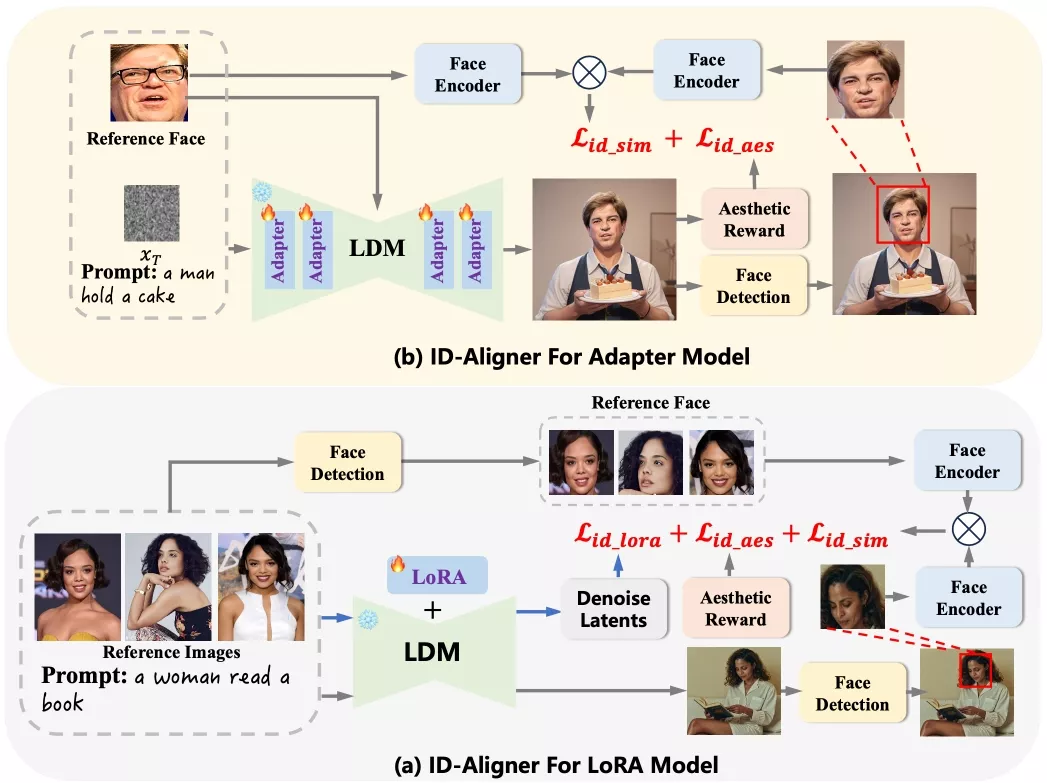
ID-Aligner为精确捕捉身份特征,开发人员实施了身份一致性回馈微调策略,借力面部检测与识别模型的回馈信息,优化图像中的身份保真度。同时,开发人员创新性地引入了身份美学回馈微调法,通过结合人工标注的审美偏好数据与自动生成的角色构图反馈,为提升图像美学质量提供了精准导向。此框架的灵活性使它能够方便地与LoRA及Adapter模型集成,确保了性能的全面提升。开发人员在SD1.5与SDXL扩散模型上的综合实验,有力证明了该方案的有效性与实用性。

例如,你想要创建一个穿着特定风格服装、特定发型和肤色的人物图像,并且希望这个人物在不同的场景和活动中保持一致的外观。使用ID-Aligner,你可以通过提供一些参考肖像图像和相应的文本提示,生成一系列新的、与参考图像中人物身份特征保持一致的图像。这些图像可以用于个性化的AI肖像、广告宣传或社交媒体内容。
主要功能:
- 身份保持增强:通过反馈学习机制,提高生成图像中人物身份特征的准确性和一致性。
- 审美提升:引入审美奖励机制,使得生成的图像不仅身份特征准确,同时在视觉上更具吸引力。
主要特点:
- 反馈学习:利用面部检测和识别模型作为奖励模型,通过反馈学习来优化身份保持。
- 通用性:适用于基于LoRA(Low-Rank Adaptation)和适配器(Adapter)的文本到图像模型。
- 性能提升:在身份保持和审美质量上均显示出优于现有方法的性能。
工作原理:
ID-Aligner框架通过以下步骤实现身份保持和审美提升:
- 面部检测与识别:使用面部检测模型定位图像中的面部,并使用面部识别模型提取面部特征。
- 身份一致性奖励:计算生成图像与参考图像之间面部特征的相似度,作为身份一致性的奖励信号。
- 审美奖励:利用人类标注的偏好数据训练奖励模型,并结合自动构建的角色结构反馈数据,来引导模型生成审美上更吸引人的图像。
- 反馈学习微调:在反馈学习阶段,使用上述奖励模型对去噪过程的中间结果进行评分,并通过微调优化扩散模型,使其更符合身份保持和审美偏好。
具体应用场景:
- AI肖像生成:根据用户提供的肖像和文本提示,生成具有该用户身份特征的图像。
- 广告和营销:生成与特定人物或品牌代言人一致的图像,用于广告宣传材料。
- 虚拟试衣:在虚拟试衣应用中,生成穿着不同服饰但保持用户身份特征的图像。
- 娱乐和社交媒体:生成具有特定身份特征的图像,用于娱乐内容制作或社交媒体个人资料。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











